도메인, 유비쿼터스 언어, 제한된 컨텍스트 이해하기
상황 설정
회사에서 새로 생긴 개발팀인 과금 및 구독 팀의의 리드 개발자가 되었다고 가정해보자. 아무래도 새로운 분야인지라 이 분야의 전문가들과 기본적인 도메인과 작동 방식에 대해 부지런히 논의해야 할 것이다. 그들의 반응은 다음과 같다.
- 리드(lead)가 처음으로 앱을 사용하는 경우, 그들은 세 가지 구독 계획을 선택해야 한다. 각각 basic, premium, exclusive이다.
- 구독 계획(subscription plan)에 따라 앱 내에서 접근할 수 있는 기능이 달라지며, 이러한 사항은 변경될 수 있다.
- 구독 계획이 생성되면 리드가 고객(customer)으로 전환되며, 고객은 이탈할 때까지 고객으로 간주한다. 이 경우, 고객은 다시 리드가 된다.
- 6개월이 지나면 이들을 잃어버린 리드(lost lead)로 간주하며, 할인 코드(discount code)를 포함할 수 있는 재참여 캠페인(re-engagement campaign)의 대상이 될 수 있다.
- 구독 계획이 생성되면 자동 이체(direct debit)를 통해 고객으로부터 자금을 확보하기 위해 반복 과금(recurring payment)를 설정한다.
자, 이제 팀으로 되돌아가서, 새 애플리케이션의 시작점으로 다음과 같은 인터페이스를 정의해보자.
package chapter2
import "context"
type UserType = int
type SubscriptionType = int
const (
unknownUserType UserType = iota
lead
customer
churned
lostLead
)
const (
unknownSubscriptionType SubscriptionType = iota
basic
premium
exclusive
)
type UserAddRequest struct {
UserType UserType
Email string
SubType SubscriptionType
PaymentDetails PaymentDetails
}
type UserModifyRequest struct {
ID string
UserType UserType
Email string
SubType SubscriptionType
PaymentDetails PaymentDetails
}
type User struct {
ID string
PaymentDetails PaymentDetails
}
type PaymentDetails struct {
stripeTokenID string
}
type UserManager interface {
AddUser(ctx context.Context, request UserAddRequest) (User, error)
ModifyUser(ctx context.Context, request UserModifyRequest) (User, error)
}이와 같이 인터페이스를 정의하였다. 차후 DDD에 대해 더 자세히 알아보면서 이 코드를 다시 확인할 것이다.
도메인(Domain)과 서브도메인(Sub-Domain)
앞선 상황 설정 장에서 결제 및 구독 시스템에 대한 간략한 개요를 살펴보았다. 이러한 것들이 바로 도메인이다. Eric Evans에 따르면, 도메인은 “지식, 영향, 또는 활동의 영역”이다.
도메인은 DDD의 중심 개체로, 모든 언어와 시스템 전반에서 우리가 모델링해야 할 대상이다. 도메인을 떠올리는 또 다른 방법은 비즈니스 세계에서 바라보는 것이다. Domain Driven Design이라는 용어를 Business Problem-Driven Design으로 읽는다고 생각해보면 된다.
도메인을 정의하는 것은 어려운 문제이며, 항상 이 예제에서처럼 명확한 것은 아니다. 이 예제에서는 결제와 구독이라는, 확실히 구분되는 두 개의 도메인이 있다. 일부 팀에서는 이 두가지를 단일 도메인으로 간주할 수도 있지만, 크게 상관은 없다. DDD는 과학이 아니다.
대규모 회사에서는 도메인을 중심으로 팀을 구성하는 경우가 많다. 새로운 도메인이 발견되고 팀이 성장함에 따라, 새로운 도메인에 기반한 팀이 생겨날 수도 있을 것이다.
도메인과 서브도메인은 거의 같은 의미라고 볼 수 있지만, 상위 도메인의 자식 도메인임을 나타내고자 할 때 주로 서브도메인을 사용한다. 이 예제에서의 결제와 구독이라는 도메인은 더 큰 비즈니스 도메인의 서브도메인이라고 볼 수 있다.
유비쿼터스 언어(Ubiquitous Language)
유비쿼터스 언어는 도메인 전문가와 기술 전문가가 공통으로 사용하는 언어이다.
앞선 상황 설정장에서, 전문가들이 대화에서 사용했던 일부 단어를 이탤릭체 처리하였다. 이러한 용어들은 다른 회사나 팀에서와는 달리 특정한 의미를 갖는다. 가령 이 팀에서의 고객은 마케팅 팀에서는 다른 의미를 가질 것이다.
유비쿼터스 언어는 요구 사항이나 시스템 설계를 논의할 때, 그리고 소스코드 자체에서도 사용되어야 한다. 또한 발전해야 하기 때문에, 언어를 주기적으로 평가하고 업데이트하는 데 시간을 할애해야 한다.
물론 신경을 많이 써야 하는 만큼의 이점이 있다. 다음과 같다.
유비쿼터스 언어의 이점
IT 프로젝트가 실패하는 주요 이유 중 하나는 요구 사항이 번역 과정에서 누락되기 때문이다. 이를테면 비즈니스 담당자가 고객당 여러 계정을 사용할 수 있게끔 요구했다고 해보자. 하지만 시스템에는 고객 엔티티가 존재하지 않는다. 과거에 고객당 계정 하나를 사용할 것이라고 가정하고 설계된 시스템이기 때문이다. 그렇다면 이 변경 사항은 사소한 변경 사항이 아니라, 몇 분기에 걸쳐 진행될 수도 있는 중대한 프로젝트가 된다. 또한, 설명에서 유저라는 단어가 아니라 사용자라는 단어를 사용하고 있다. 이는 사소한 차이처럼 보이지만, 엔지니어가 비즈니스적 관점에서 생각하지 않고 유비쿼터스 언어를 사용하지 않았다는 점이 이러한 불변성을 놓친 이유일 수 있다.
앞서 유비쿼터스 언어는 소스코드 자체에도 적용되어야 한다고 언급하였다. 우리가 작성하였던 코드를 살펴보자.
type UserType = int
type SubscriptionType = int
const (
unknownUserType UserType = iota
lead
customer
churned
lostLead
)
const (
unknownSubscriptionType SubscriptionType = iota
basic
premium
exclusive
)이렇게 코드에 유비쿼터스 언어가 잘 적용되어 있다. 도메인 전문가가 구독에 관련된 이야기를 꺼낼 때마다, 시스템 표현을 찾기 위해 애쓸 필요가 없어진다.
코드에서 UserType이란 것도 정의했는데, 도메인 전문가와의 대화에서는 사용자라는 단어를 사용하지 않았다.
따라서 이 단어를 유비쿼터스 언어 단어 사전에 추가할지 논의하여, 사용자라는 단어를 사용할 때 모두가 같은 것에 대해 이야기하고 있는지 확인할 수 있는 좋은 기회가 될 것이다.
다음 부분 코드는 이렇다.
type UserAddRequest struct {
UserType UserType
Email string
SubType SubscriptionType
PaymentDetails PaymentDetails
}
type UserModifyRequest struct {
ID string
UserType UserType
Email string
SubType SubscriptionType
PaymentDetails PaymentDetails
}
type User struct {
ID string
PaymentDetails PaymentDetails
}
type PaymentDetails struct {
stripeTokenID string
}
type UserManager interface {
AddUser(ctx context.Context, request UserAddRequest) (User, error)
ModifyUser(ctx context.Context, request UserModifyRequest) (User, error)
}일단 이런 코드는 흔히 볼 수 있는 코드이다 보니, 처음에 보면 별 문제 없어 보인다.
드디어 사용자라는 단어를 정의하기로 도메인 전문가와 협의했다. 이제 사용자는 상태에 관계 없이 앱을 사용하는(혹은 사용했던) 사람을 나타낸다. 그들의 가능한 상태는 lead, lost lead, customer, churned가 있고, 미래에 상태가 추가될 수도 있다.
이러한 정의를 감안할 때, AddUser 함수는 별로 좋은 생각이 아닌 것 같다.
우리 도메인에는 사용자 추가라는 개념이 없으며, 도메인 전문가에게 이런 문장을 사용하면 혼란을 줄 것이다.
일단 도메인의 시스템 표현과 실세계 표현 사이의 매핑으로 끝맺음을 짓지만, 강력한 유비쿼터스 언어를 만들기 위해 투자한 시간으로부터 이득을 얻지 못했다.
다시 되돌아가서, 우리는 새로 앱을 사용하는 사람을 리드라고 부르고, 그들이 구독을 하면 고객으로 전환하기로 하였다. 이에 기반하여 코드를 다음과 같이 일부 수정할 수 있다.
type LeadRequest struct {
email string
}
type Lead struct {
id string
}
type LeadCreater interface {
CreateLead(ctx context.Context, request LeadRequest) (Lead, error)
}
type Customer struct {
leadID string
userID string
}
func (c *Customer) UserID() string {
return c.userID
}
func (c *Customer) SetUserID(userID string) {
c.userID = userID
}
type LeadConvertor interface {
Convert(ctx context.Context, subSelection SubscriptionType) (Customer, error)
}
func (l Lead) Convert(ctx context.Context, subSelection SubscriptionType) (Customer, error) {
// TODO: implement
panic("implement me")
}이 코드는 더 합리적이며, 실제 세계를 더 잘 반영한다. 이제 전문가와 시스템에 대해 이야기할 때, 리드와 고객, 구독, 그리고 리드의 전환이라는 단어를 사용할 수 있으며, 이는 모두 도메인에 대한 유비쿼터스 언어이다.
강력한 유비쿼터스 언어를 만드는 방법
강력한 유비쿼터스 언어를 만드는 지름길은 없고, 도메인 전문가와의 충분한 대화를 거치는 것이 모든 중요한 언어를 포착하는 최선의 방법이다. 한 가지 좋은 방법은 회의에 참가하여 회의록을 작성하는 것이다. 회의 중 이해하지 못한 언어를 적어두고 회의가 끝나면 도메인 전문가에게 물어보는 것이다. 이를 유비쿼터스 언어 단어 사전에 추가하고, 다른 동료들과 공유할 수 있다.
유비쿼터스 언어를 적용할 때의 주의점
여러 프로젝트, 팀, 또는 회사 전체에 유비쿼터스 언어를 적용하고 싶을 수도 있지만, 이는 좋은 선택이 아니다. Evans에 따르면 유비쿼터스 언어는 하나의 제한된 컨텍스트에서만 적용되어야 한다. 유비쿼터스 언어는 엄격할 때 가장 잘 작동하기 때문이다. 고객(customer)이나 유저(user)같은 특정한 단어를 다른 모든 분야에 적용하려 한다면, 해당 단어는 엄격함을 잃고 혼란을 야기할 것이다.
제한된 컨텍스트
구독 시스템에 대한 개요를 시작하였고, 시스템을 나타내는 유비쿼터스 언어에 대해서도 알아보았다. 그러던 와중, 만약 사업의 다른 분야에서 온 누군가가 고객(customer)에 대해 논의하기 위에 온다면 어떻게 해야 할까? 우리가 가장 먼저 할 일은 제한된 컨텍스트 내에서 고객의 의미가 다를 수 있기 때문에, 먼저 이를 정의하는 것이다.
제한된 컨텍스트는 큰 모델을 작은 조각으로 나누어, 이해하기 쉽게끔 모델의 구조를 명시하는 것이다. 한 컨텍스트에서 단어를 정의하면, 다른 컨텍스트에서 동일한 의미일 필요는 없다. 가령 우리의 구독 시스템을 다이어그램으로 나타내면 다음과 같을 것이다.
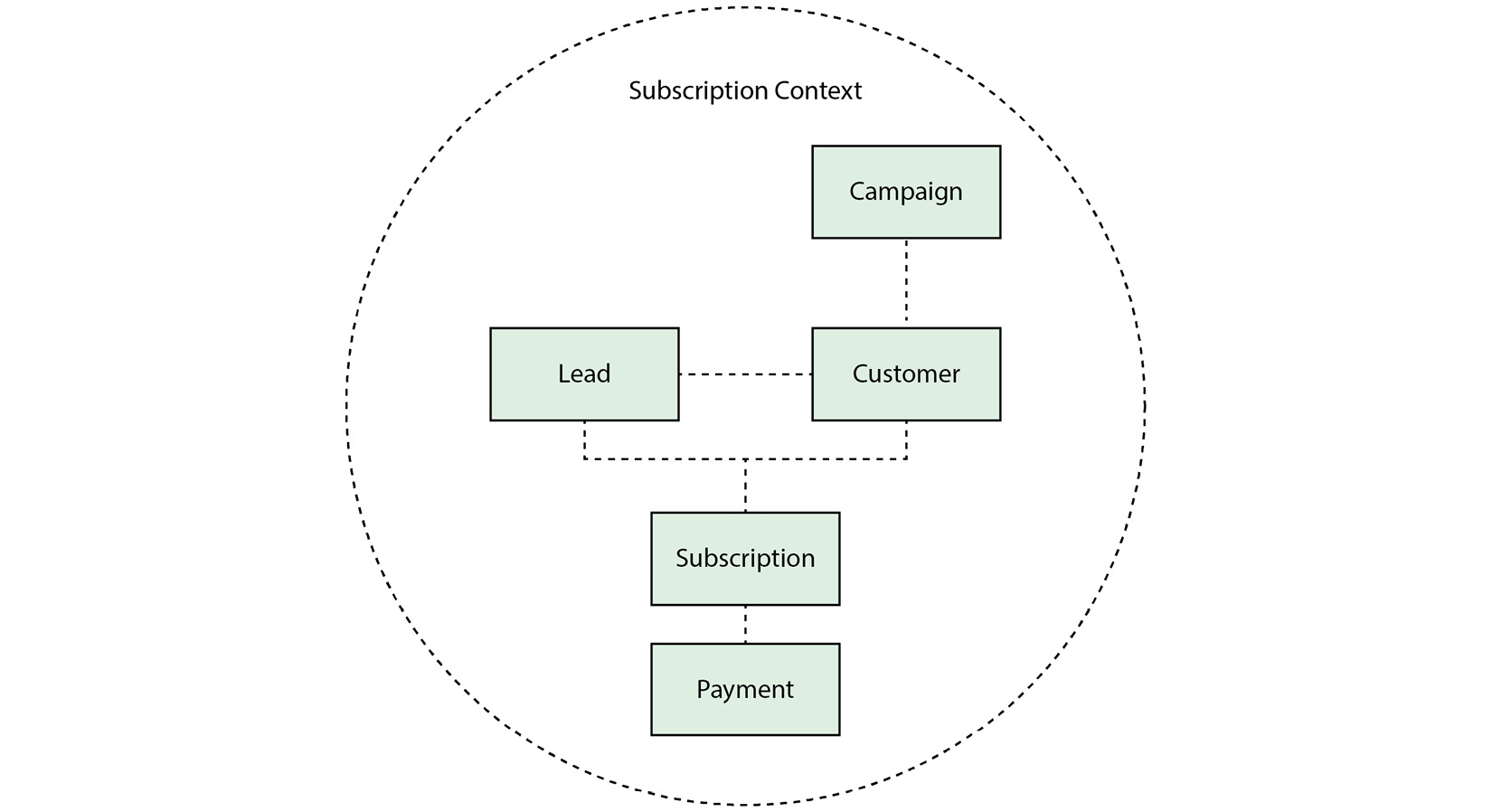
하지만 마케팅 팀과 이야기하고 그들의 컨텍스트를 이해하고 나면 다음과 같은 관계를 정의할 수 있다.
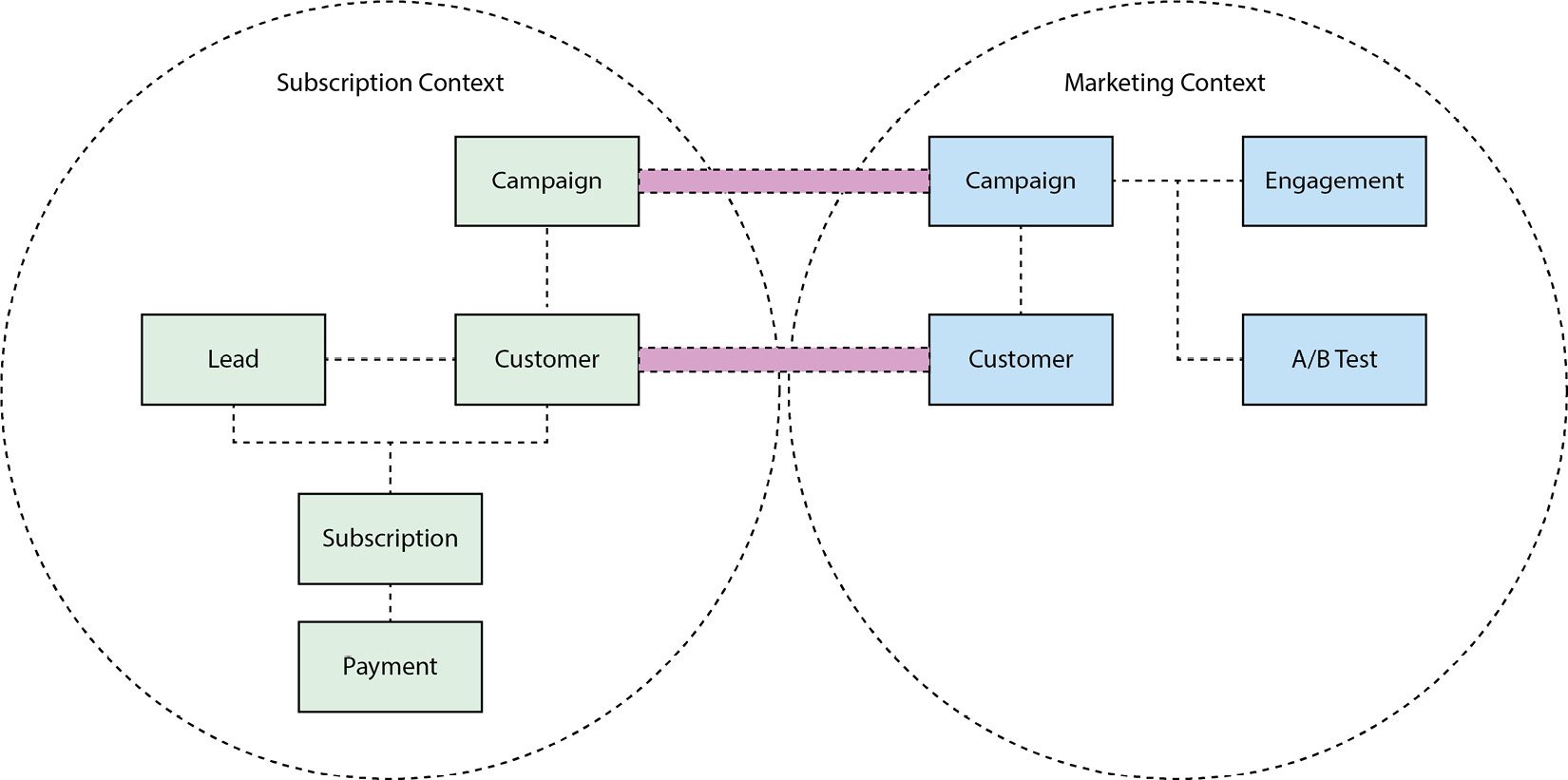
서로 다른 제한된 컨텍스트 사이에서 캠페인(campaign)과 고객(customer) 사이에 연결된 선은 동일한 용어를 사용하지만 모델이 다르며, 그들 사이에 일부 매핑이 가능함을 나타낸다. 이러한 내용은 다음 단락에서 보다 자세히 설명한다
두 컨텍스트에서 모두 캠페인(campaign)과 고객(customer)을 중요하게 생각하지만, 서로 다른 컨텍스트이기 때문에 각 컨텍스트에서 이를 모델링하고 이야기하는 방법은 같을 필요가 없다. 이 예제는 간단한 예제이지만 시스템이 진화하고 복잡해질 수록 경계를 정의하는 것이 점점 유의미해질 것이다.
위 그림처럼 제한된 컨텍스트 사이에서 통신해야 하는 경우가 많기 때문에, 모델들의 무결성을 유지해야 한다. 이에는 몇 가지 패턴이 있는데, 세 가지 주요 패턴은 다음과 같다.
- Open Host Service
- Published Language
- Anti-Corruption Layer
Open Host Service
Open Host Service는 다른 시스템(또는 서브시스템)에서 우리의 시스템에 접근할 수 있도록 하는 서비스이다. 팀의 제약 조건과 기술적인 요소에 따라 사정이 다를 수 있기 때문에, Evans는 이 부분의 구현에 대해서 설명을 모호하게 두었다. 일반적으로 Open Host Service는 RPC로 구현되며, RPC는 RESTFul API, gRPC 등으로 구현될 수 있다.
Open Host Service를 시각적으로 나타내면 다음과 같다.
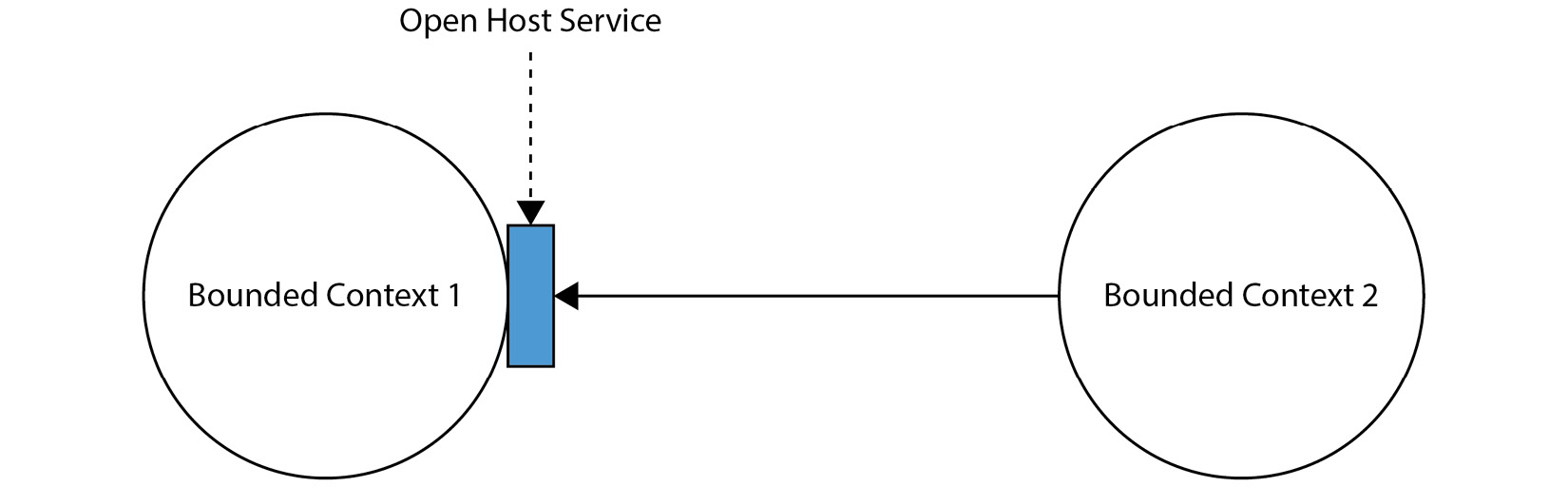
그림에서 파란 직사각형은 제한된 컨텍스트의 노출된 부분을 의미한다. 우리의 과금 및 구독 모델을 예로 들면, 마케팅 팀이 우리 컨텍스트 내에서 다양한 정보를 얻을 수 있도록 엔드포인트를 노출할 수 있다. 이를테면 다음과 같다.
package chapter2
import (
"context"
"encoding/json"
"github.com/gofiber/fiber/v2"
"net/http"
)
type UserHandler interface {
IsUserPaymentActive(ctx context.Context, userID string) bool
}
type UserActiveResponse struct {
IsActive bool
}
func router(u UserHandler, app *fiber.App) {
app.Get("/user/{userID}/payment/active", func(ctx *fiber.Ctx) error {
uID := ctx.Query("userID")
if uID == "" {
return ctx.SendStatus(http.StatusBadRequest)
}
isActive := u.IsUserPaymentActive(ctx.UserContext(), uID)
b, err := json.Marshal(UserActiveResponse{IsActive: isActive})
if err != nil {
return ctx.SendStatus(http.StatusInternalServerError)
}
return ctx.Send(b)
})
}위 코드는 /user/{userID}/payment/active에서 사용 가능한 HTTP 엔드포인트를 노출하는 코드이다.
이를 통해 다른 팀에서 우리의 시스템에 접근하여 사용자가 활성 구독을 가지고 있는지 확인할 수 있다.
원본 코드는 gorilla mux를 통해 작성되어 있지만, 여기서는 fiber를 사용하여 작성하였다.
Published Language
유비쿼터스 언어가 팀의 내부에서 사용하는 언어라면, Published Language는 그 반대 개념이다. 만약 우리 팀이 Open Host Service를 통해 다른 팀에 시스템 일부를 노출하기로 결정하였다면, 서로 다른 제한된 컨텍스트에서 어떤 것을 노출시킬 것인지에 대한 정의를 명확히 해야 한다.
앞서 언급한 HTTP 서버와 같이 GET /{id}/user 엔드포인트를 노출시킨다고 한다면,
다른 팀이 입/출력 스키마에 대해 알 수 있도록 언어를 개시해야 한다.
가장 인기있는 방식은 OpenAPI 또는 gRPC를 사용하는 것이다.
OpenAPI
일반적으로 Swagger와 같이 사용하는 그 OpenAPI이다. 대충 이렇게 생겼다.
swagger: '2.0'
info:
description: 'Public documentation for payment & subscription System'
version: '1.0.0'
title: 'Payment & Subscription API'
contact:
email: 'ourteam@subs.com'
host: 'api.payments.com'
schemes:
- 'https'
paths:
/users:
get:
summary: 'Return details about users'
operationId: 'getUsers'
produces:
- 'application/json'
responses:
'200':
description: 'successful operation'
schema:
$ref: '#/definitions/User'
'400':
description: 'bad request'
'404':
description: 'users not found'
definitions:
User:
type: 'object'
properties:
id:
type: 'integer'
...자동으로 직관적인 UI를 만들어준다는 장점이 있다.
특히 golang의 경우 oapi-codegen이라는 라이브러리가 좋다고 한다. 해당 라이브러리에 대한 Github 링크는 여기를 참조하자.
자동으로 OpenAPI 파일을 생성해볼 것이다. 먼저 oapi-codegen을 설치해야 한다.
go install github.com/deepmap/oapi-codegen/cmd/oapi-codegen@latest그리고 다음과 같은 설정 파일을 작성한다. 생성된 코드가 속할 패키지와, 생성된 코드가 저장될 파일을 명시해준다.
package: oapi
output: ./openapi.gen.go
generate:
models: true이제 명령어를 쳐보자!
oapi-codegen --config=config.yml ./oapi.yaml이렇게 하면 openapi.gen.go 파일이 생기면서, 구현할 수 있는 서버용 인터페이스가 생긴다.
API 문서를 업데이트할 때마다 이 명령어를 재실행하면 새로운 서버 정의를 생성할 수 있다.
클라이언트 코드를 생성하는 것도 간단하다. config.yml 파일 맨 끝에 client: true만 추가하고 이전 명령어를 재실행하면 된다. 여기서는 생략해야지~
OpenAPI 사양을 업데이트하고 클라이언트를 업데이트하고자 하는 경우, 이전에 쳤던 명령어를 다시 실행시키기만 하면 된다. 이러한 작업을 Continuous Integration 파이프라인에 추가하면, 소비자 팀에서 필요할 때마다 최신 버전을 얻을 수 있을 것이다.
팀이 REST API를 사용하는 데 익숙하다면 OpenAPI는 꽤 괜찮은 Published Language이다. OpenAPI는 문서 우선이므로 외부 문서가 항상 최신으로 유지되는 것을 보자아며, 이는 굉장한 이점이다. 또한 코드가 자동으로 생성되므로, 별도의 노력 없이 다양한 유즈 케이스를 지원할 수 있다.
하지만 OpenAPI보다 성능이 더 좋은 대안들이 많다. 그리고 OpenAPI는 기본적으로 주요 변경 사항에 대한 보호를 제공하지 않는다. 이를테면 문서에서 어떤 필드를 제거했지만 다른 팀이 이에 의존하는 경우, 그들의 워크플로우가 깨질 수 있다.
이러한 문제를 해결하고 추가적인 기능을 제공하는 gRPC를 살펴보록 하자.
gRPC
gRPC는 대규모 원격 통신을 위해 Google에서 개발된 통신 프레이뭐크로, HTTP/2를 기반으로 하며 로드 밸런싱, 추적, 인증, 양방향 스트리밍, 헬스 체크 등의 기능을 제공한다.
gRPC는 전송하는 페이로드를 바이너리로 직렬화하기 때문에 더 빠르고 효율적이다. 또한 gRPC에서 클라이언트는 원격 서버의 코드를 마치 로컬 코드를 호출하듯 사용할 수 있다. 그리고, gRPC는 다양한 언어와 OpenAPI같은 다양한 프레임워크를 지원한다.
원격 서버의 메소드를 호출하기 위해서는 먼저 Protobuf 파일을 작성해야 한다.
Protobuf 파일은 주로 .proto 확장자를 가지며, 언어에 구애받지 않는다.
Protobuf 파일은 다음과 같은 형태를 가진다.
syntax = "proto3";
option go_package = "github.com/jhseoeo/Golang-DDD/chapter2/grpc/user";
package user.v1;
message User {
int64 id = 1;
string username = 2;
string email = 3;
}
service UserService {
rpc CreateUser (CreateUserRequest) returns (CreateUserResponse) {}
}
message CreateUserRequest {
User user = 1;
}
message CreateUserResponse {
bool success = 1;
}이를 통해 서비스, 그리고 요청 및 응답 객체를 정의하고, 클라이언트 코드와 서버 코드를 생성할 수 있다.
gRPC는 REST-API 기반인 OpenAPI에 비해 시작하기가 조금 더 어렵다. 또한 코드를 생성하는데 필요한 일부 도구를 설치 및 사용하기가 다소 어려울 수 있다.
먼저, protobuf 컴파일러를 설치하고, protoc 명령어를 활성화하기 위해 path를 업데이트해줘야 한다.
sudo apt-get install protobuf-compiler
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest
export PATH="$PATH:$(go env GOPATH)/bin"이후, 프로젝트 폴더에서 다음과 같이 명령어를 입력한다.
protoc --go_out=. --go_opt=paths=source_relative
--go-grpc_out=. --go-grpc_opt=paths=source_relative
grpc/userservice.proto이렇게 하면 userservice.pb.go와 userservice_grpc.pb.go 파일이 생성되며, 해당 파일을 통해 서버와 클라이언트 코드를 작성할 수 있다.
gRPC에 관련한 내용은 아마도 다른 포스트에서 다룰 예정이다.
Anti-Corruption Layer
Anti-Corruption Layer는 Adapter Layer라고도 하며, 다른 시스템의 모델을 변환하기 위해 사용된다. Open Host Service와 잘 어울리는 상호보완적인 패턴이라고도 할 수 있다. 가령 마케팅 팀의 published language에서는 캠페인(campaign)을 다음과 같이 정의할 수 있다.
{
"id": "4cdd4ba9-7c04-4a3d-ac52-71f37ba75d7f",
"metadata": {
"name": "some campaign",
"category": "growth",
"endDate": "2023-04-12"
}
}하지만 우리 팀에서의 캠페인은 내부적으로 이와 같이 정의되어 있다고 해보자.
type Campaign struct {
id string
title string
goal string
endDate time.Time
}두 모델은 거의 동일한 정보를 가지고 있지만, 데이터 필드의 이름이나 포맷이 약간 다르다. 우리의 캠페인 모델을 마케팅 팀과 완전히 동일하게 바꾸면 해결되지만 이는 DDD의 원칙에 위배된다. 이러한 경우 Anti-Corruption Layer를 사용할 수 있다.
package chapter2
import (
"errors"
"time"
)
type Campaign struct {
ID string
Title string
Goal string
EndDate time.Time
}
type MarketingCampaignModel struct {
Id string `json:"id"`
Metadata struct {
Name string `json:"name"`
Category string `json:"category"`
EndDate string `json:"endDate"`
} `json:"metadata"`
}
func (m *MarketingCampaignModel) ToCampaign() (*Campaign, error) {
if m.Id == "" {
return nil, errors.New("campaign ID cannot be empty")
}
formattedDate, err := time.Parse("2006-01-02", m.Metadata.EndDate)
if err != nil {
return nil, errors.New("endDate was not in a parsable format")
}
return &Campaign{
ID: m.Id,
Title: m.Metadata.Name,
Goal: m.Metadata.Category,
EndDate: formattedDate,
}, nil
}이와 같이 MarketingCampaignModel을 Campaign으로 변환하는 과정에서 데이터가 변환 가능한지 검증하는 로직이 포함되어 있다.
복잡한 시스템에서는 Anti-Corruption Layer의 역할이 더 커질 수 있고, 이전 시스템에서 현 시스템으로 마이그레이션하는 과정에서도 사용될 수 있다.
하지만 추가적인 오버헤드나 실패가 발생할 수 있는 지점이 생겨난다는 점을 유의해야 한다.
모든 DDD 패턴 중, Anti-Corruption Layer는 DDD 외부에서 가장 많이 사용되는 패턴이다. 시스템을 분리(디커플링)된 상태로 유지할 때 효과적이다.
References
[
[Matthew Boyle, Domain-Driven Design with Golang』, O'Reilly Media, Inc.](https://learning.oreilly.com/library/view/domain-driven-design-with/9781804613450/)