분산 시스템에 DDD 적용하기
이전 포스트에서는 마이크로서비스 아키텍처에서 DDD를 적용하는 방법에 대해 알아보았다. 이번 포스트에서는 보다 더 큰 규모의 분산 시스템에서 DDD를 적용하고, CQRS(Command Query Responsibility Segregation)와 Event Driven Architecture(이하 EDA) 등의 패턴에 대해서 알아볼 것이다. 또한 message bus나 resilient pattern 등 분산 시스템에서 필요한 패턴에 대해서도 알아볼 것이다.
분산 시스템
분산 시스템은 여러 컴퓨팅 자원들이 네트워크로 연결되어 동작하는 시스템으로, 단일 컴퓨터로 수행하기 어려운 작업을 여러 컴퓨터가 나눠서 수행함으로써 더 효율적으로 수행할 수 있다.
분산 시스템의 특징은 다음과 같다
- Scalability: 워크로드에 따라 시스템의 크기를 조절할 수 있음.
- Fault Tolerance: 시스템의 일부가 실패하였을 때, 이것이 전체 시스템의 실패로 이어지지 않음.
- Transparency: 사용자는 시스템이 단일 컴퓨터에서 동작하는지, 여러 컴퓨터에서 동작하는지 알 수 없음.
- Concurrency: 시스템의 여러 부분이 동시에 실행될 수 있음.
- Heterogeneity: 시스템의 여러 부분이 다른 하드웨어, 운영체제, 프로그래밍 언어 등으로 구성될 수 있음.
- Replication: Fault Tolerance를 위해 시스템의 일부분이 Redundant하게 구성될 수 있음.
하지만 단일 컴퓨터에서 동작하는 시스템과 달리, CAP 이론에 따라 분산 시스템은 Consistency, Availability, Partition Tolerance 중 2개만 만족할 수 있다.
- Consistency: 모든 노드가 동일한 데이터를 가지고 있음.
- Availability: 모든 요청에 대해 응답을 받을 수 있음.
- Partition Tolerance: 노드간의 통신이 실패하더라도 시스템이 동작할 수 있음.
따라서 작업을 취소하여 Availability를 포기하는 대신 Consistency를 충족시키거나, 작업을 취소하지 않고 Availability를 챙기는 대신 Consistency를 포기하는 등의 선택지 중 하나를 선택하여야 한다.
CAP 이론과 데이터베이스
CAP이론은 데이터베이스의 분류에도 적용된다. 이를테면 MySQL과 같은 RDBMS는 Partition Tolerance를 포기하고 Consistency와 Availability를 만족시키는 ACID 트랜잭션을 지원한다. 반면 MongoDB와 같은 NoSQL은 Availability를 포기하고 Consistency와 Partition Tolerance를 만족시키는 CP 데이터베이스이다.
MongoDB는 한 개의 메인 노드와 여러 개의 서브 노드로 구성되어 있다. 메인 노드는 Write 오퍼레이션을 처리하고, 이러한 Write 오퍼레이션은 서브 노드로 복제된다. Read 오퍼레이션은 메인 노드와 서브 노드 모두에서 처리할 수 있다. 단, 서브 노드에서 처리하는 Read 오퍼레이션은 메인 노드에서 처리하는 Read 오퍼레이션보다 최신의 데이터를 보장하지 않는다.
만약 메인 노드가 다운된다면, 가장 최신의 데이터를 가진 서브 노드를 메인 노드로 승격시키고, 이전에 메인 노드였던 노드를 서브 노드로 변경한다. 이 때 잠깐 데이터베이스가 사용 불가능해지지만, 곧 데이터베이스가 사용 가능해진다.
반면, Cassandra는 AP 데이터베이스로, Consistency를 포기하고 Availability와 Partition Tolerance를 만족시킨다. Cassandra는 여러 개의 노드로 구성되어 있고, Write 오퍼레이션은 모든 노드에 복제된다. 이 때 메인 노드라는 개념이 없기 때문에 모든 노드가 Write 오퍼레이션을 처리할 수 있으며, SPOF가 없기 때문에 데이터센터가 다운되어도 사용 가능하다. 또한 Consistent hashing을 통해 데이터를 분산시키기 때문에 수평적 확장이 가능하다.
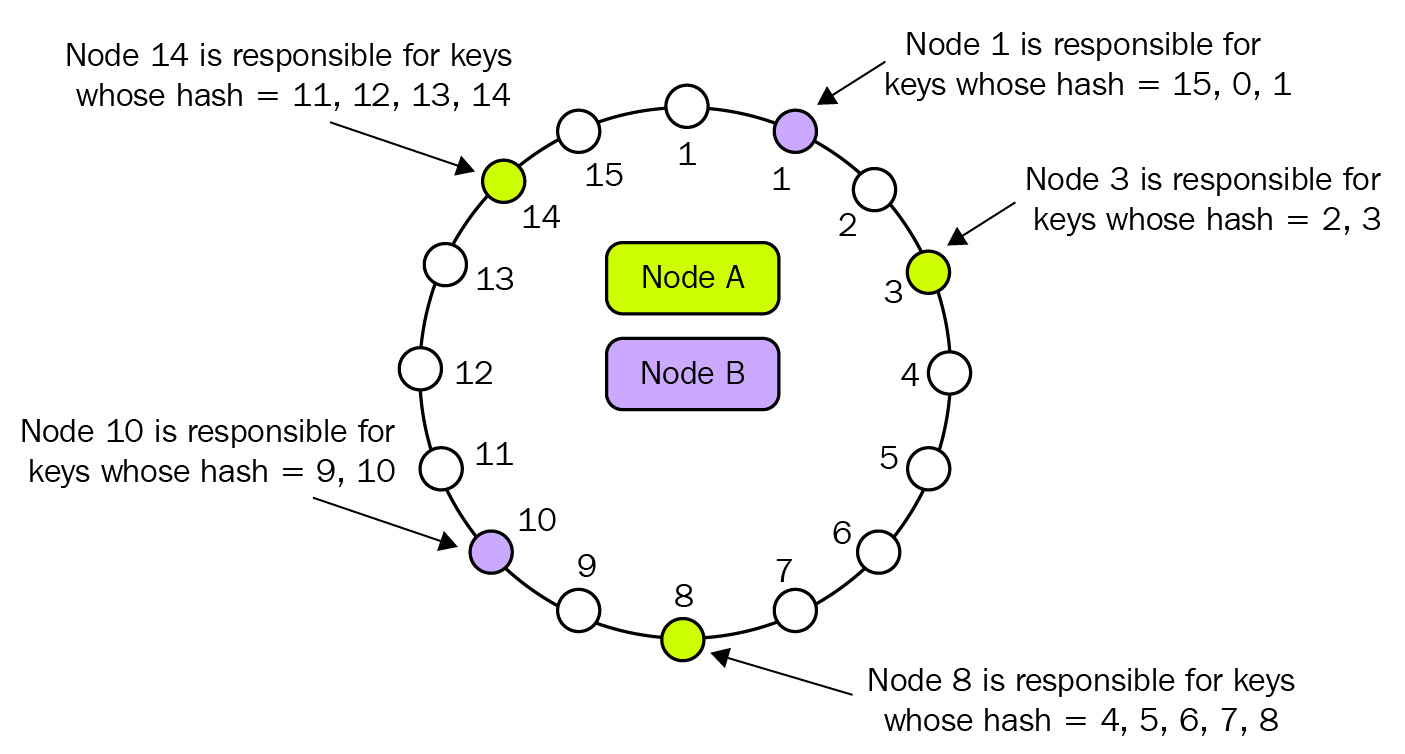
Cassandra는 기존의 RDBMS와는 완전히 다르게 동작하기 때문에 익숙해지기 다소 어려울 수 있다. 하지만 대규모 분산 시스템을 사용하는 경우처럼, 적합한 상황에서 사용한다면 Cassandra는 매우 유용한 데이터베이스가 될 수 있다.
분산 시스템 패턴
분산 시스템이 점점 복잡해짐에 따라, 이를 관리하기 위한 패턴들이 등장하였다. 이번 포스트에서는 이러한 패턴들 중, CQRS(Command Query Responsibility Segregation)와 EDA(Event Driven Architecture)에 대해 알아볼 것이다.
CQRS
모놀리식 아키텍처에서는 동일한 데이터 모델과 레포지토리를 사용하여 데이터를 읽고 쓴다. 대부분의 유스케이스에서는 이러한 방식이 잘 동작하지만, 시스템이 복잡해짐에 따라 데이터와 서비스 계층 사이의 쿼리와 매핑을 관리하기 어려워진다. 또한 읽기와 쓰기에 대한 요구사항이 다른 경우가 많다. 가령 로그 수집 시스템은 데이터 읽기 빈도보다 쓰기 빈도가 훨씬 높다.
가령 사용자가 웹사이트에 접속하면, 쿼리(Query) 모델을 통해 관련된 데이터를 읽어와서 사용자에게 보여줄 수 있다. 만약 사용자가 배송지를 변경하는 등 무언가를 변경하기 위해 특정한 동작을 취하면, 시스템은 이 동작을 수행하기 위한 명령(Command)을 내릴 것이다.
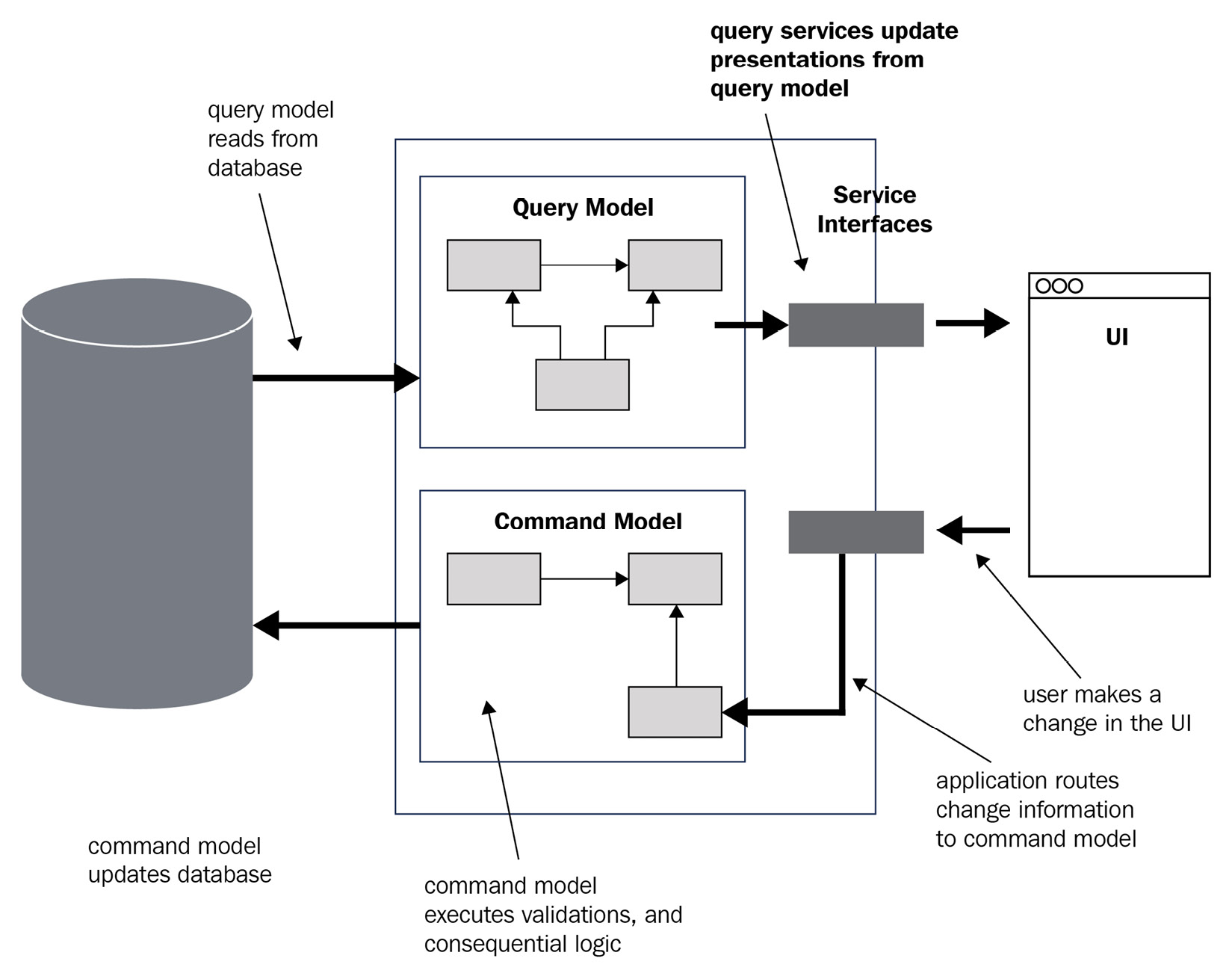
CQRS가 DDD에 꼭 필요한 것은 아니지만, DDD와 함께 사용하면 복잡한 시스템의 시스템의 복잡성을 줄일 수 있다. CQRS를 사용하기 위해 따라야 할 규칙은 다음과 같다.
- 모든 메소드는 동작을 수행하는 Command 또는 질문에 답하는 Query를 수행해야 하며, 둘 다 수행해서는 안 된다.
- Query가 응답을 변경해서는 안되며, Query가 변경되어서도 안 된다.
Golang의 경우, 다음과 같은 규칙으로 CQRS를 구현할 수 있다.
- 메소드가 데이터베이스를 변경하는 경우, 이는 Command이며, error 또는 nil만을 반환한다.
- 메소드가 값을 반환하는 경우, 이는 Query이며, 데이터베이스를 변경하지 않는다.
모놀리식 아키텍처에서의 CQRS는 최선의 방법이 아니지만, 분산 시스템에서는 CQRS가 매우 유용하다. 특히 다음의 내용인 Event Driven Architecture와 함께 사용하면, 시스템의 복잡성을 줄이는데 매우 큰 도움이 된다.
Event Driven Architecture
EDA(Event Driven Architecture)는 분산 시스템이 이벤트를 생성, 감지, 반응하는 방식으로 동작하는 아키텍처이다. 이벤트는 시스템의 상태 변화를 나타낸다. Domain-Driven 시스템에서 입출력 이벤트는 메시지 버스를 통해 다른 시스템으로 전달되며, 이러한 메시지 버스는 RabbitMQ, Kafka 등이 있다.
이벤트는 이벤트 헤더와 이벤트 바디로 구성된다. 이벤트 헤더는 메시지가 생성된 시간의 타임스탬프, 메시지를 생성한 시스템에 대한 정보, 메시지의 UUID 등 메시지에 대한 메타데이터를 포함한다. 그리고 event의 바디는 변경된 상태에 대한 정보를 포함한다. event 바디의 예시는 다음과 같다.
{
"event_type": "user.logged_in",
"user_id": 135649039
}이와 같은 JSON 외에도 Protobuf, Avro 등 여러 포맷이 존재한다.
이벤트 기반 시스템에서는 로깅, 헬스체크, 동적 프로비저닝 등 다양한 목적의 메시지가 생성되어 전달된다.
DDD에서는 도메인 이벤트에 초점을 맞춘다. 위 예시에서는 user.logged_in이 도메인 이벤트에 해당하며, 한 마이크로서비스에서 다른 마이크로서비스로 전달된다.
보통 한 도메인 이벤트는 특정 제한된 컨텍스트에서만 의미가 있다. 모든 시스템에서 모든 도메인 이벤트를 수신하지 않는다. 우리의 제한된 컨텍스트에서 유효한 도메인 이벤트의 경우, 이를 수신하여 도메인 모델에 맞게 변환하고, 동작을 수행한다.
각각의 도메인 이벤트는 그 자체로는 큰 의미가 없을 수 있다. 여러 도메인 이벤트를 조합함으로써 의미 있는 결과를 얻을 수 있다. 다음의 사진은 이를 설명한다.
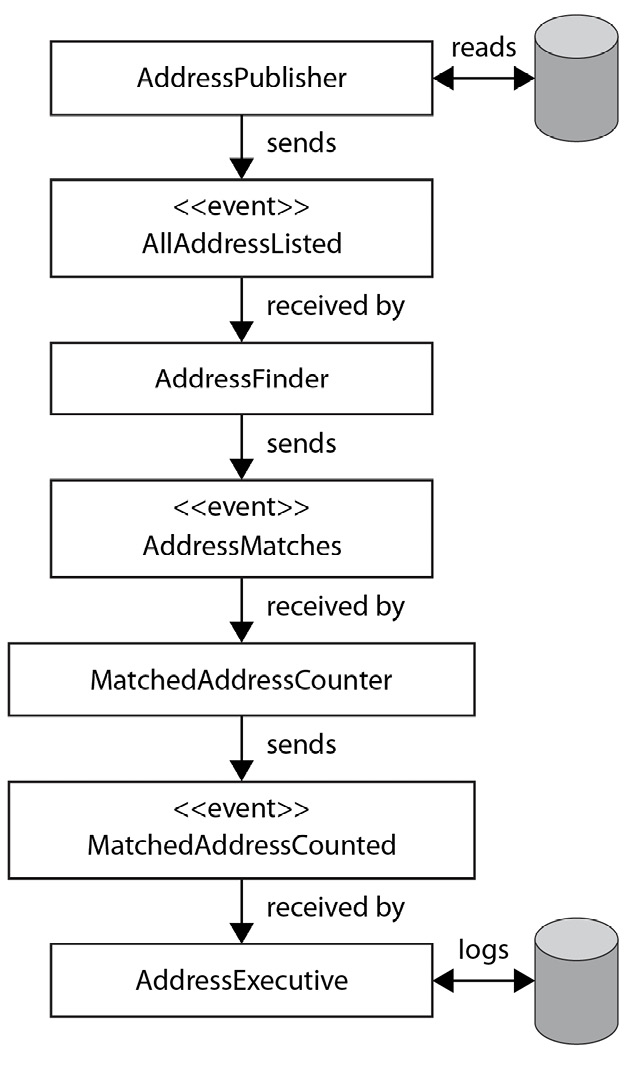
이 사진은 long-term 프로세스의 파이프라인과, 파이프라인의 각 단계에서 생성 및 전달되는 이벤트를 보여준다.
이와 같은 파이프라이닝은 시스템을 매우 유연하게 만들어준다. AddressMatches 이벤트에 관심이 있는 다른 이벤트는 이를 구독하여 이벤트를 수신할 수 있다.
또한 이 파이프라인을 수정하여 미래의 추가적인 비즈니스 요구사항을 처리할 수도 있다.
이벤트 기반 시스템의 주요 문제는 데이터가 분산되어 있다는 점이다. 특히 이벤트 기반 시스템에서 문제를 처리하는 도중 문제가 발생하였을 때 어떻게 해야 하는지에 대한 문제는 매우 중요하다. 다음 장에서는 이러한 문제를 해결하기 위한 몇 가지 주요 패턴에 대해 알아볼 것이다.
실패 처리
이전에 CAP 이론, 그리고 분산 시스템에서 어떤 절충안을 선택해야 하는지에 대해 알아보았다. 또한 분산 시스템에서는 통제할 수 없는 외부 요인으로 인해 실패가 발생하기도 아며, 에지 케이스에서도 실패가 발생할 수 있다. 하지만 전달 속도를 위해서는 이러한 실패를 감수하고 적합한 방법으로 처리해야 한다.
Two-Phase Commit (2PC)
일관성은 모놀리식 아키텍처에서뿐만 아니라 분산 시스템에서도 매우 중요하다. 하지만 분산 시스템에서의 트랜잭션에 원자성을 보장하는 것은 거의 불가능하다. 따라서 이를 해결하기 위한 한 가지 방법은 작업을 두 단계로 나누는 Two-Phase Commit(2PC)이다.
- Preparation phase : 우리가 수행하려는 워크로드를 약속할 수 있는지, 각각의 서브시스템에 묻는 단계
- Completion phase : 방금 약속한 작업을 각각의 서브시스템에 전달하는 단계
Preparation phase에서는 각각의 서브시스템은 약속을 지키기 위해 필요한 작업을 모두 완료한다. 이러한 작업은 주로 리소스에 lock을 거는 것이다. 참여자가 이 약속을 이행할 수 없거나, coordinator의 요청에 일정 시간 내에 응답하지 않는다면 이 작업은 실패로 간주된다.
2PC는 Domain-Driven 시스템을 작성할 때 알아두면 꽤 유용한 패턴이다. 우리가 Domain-Driven 시스템을 작성할 때 유념해야 하는 것은 시스템이 비즈니스 도메인 모델을 최대한 반영해야 한다는 것이며, 문제가 발생하면 비즈니스 불변성이 깨지지 않도록 롤백해야 한다는 것이다. 2PC는 이러한 문제를 해결하기 위해 사용할 수 있는 패턴이다.
하지만 2PC는 차단 프로토콜이라는 단점이 있다. 2PC를 사용하면 시스템의 동시성이 저하되며, 최악의 경우 lock이 풀릴 때까지 아무런 작업도 수행할 수 없게 된다. 이를 개선하기 위한 몇 가지 패턴이 있으며, 대표적인 것이 바로 Saga이다.
Saga
Saga 패턴은 분산 환경에서 동시성을 확보하면서도 일관성을 유지할 수 있는 방법이다. Saga 패턴의 기본 원칙은 매우 간단하다. 시스템에서 수행할 각각의 작업에 대해, 롤백하는 경우 취해야 할 작업을 함께 정의하는 것이다.
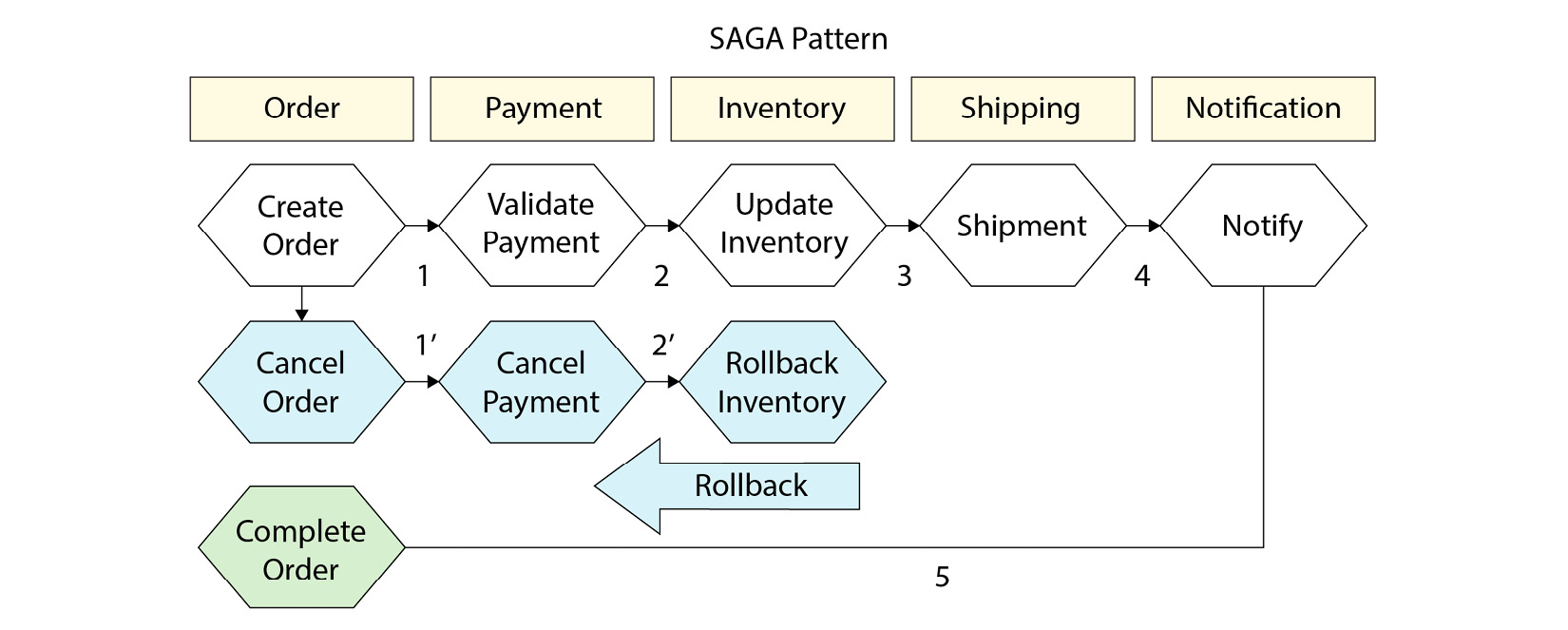
위 사진은 고객 알림을 통해 생성되는 주문의 흐름을 보여준다. 이상적인 주문 흐름의 경우 하얀색 육각형으로 표시된 작업이 순서대로 실행되겠지만, 중간에 시스템이 실패할 경우 이전에 수행한 작업을 롤백해야 한다. 가령 인벤토리 업데이트에 실패하면, 인벤토리를 롤백하고, 결제를 취소하고, 주문을 취소해야 한다. 이러한 단계들이 모두 성공하거나 롤백된다면 일관적인 시스템 상태를 유지할 수 있다.
만일 롤백 중 실패가 발생한다면 어떻게 해야 할까? Saga 패턴은 EDA와 결합하여, 보상 제어를 위한 이벤트를 발행할 수 있다. 따라서 그 이벤트를 수신하는 다른 시스템에서 자체적으로 재시도되는 등 적절하게 처리할 수 있다.
탄력적인 Saga 패턴을 구현하는 방법에 대해 모두 다루기에는 이 포스트의 범위를 벗어나지만, 무난한 Saga 패턴의 예시는 다음과 같다.
package chapter7
import "context"
type Saga interface {
Execute(ctx context.Context) error
Rollback(ctx context.Context) error
}
type OrderCreator struct{}
func (o *OrderCreator) Execute(ctx context.Context) error {
return o.createOrder(ctx)
}
func (o *OrderCreator) Rollback(ctx context.Context) error {
return o.deleteOrder(ctx)
}
func (o *OrderCreator) createOrder(ctx context.Context) error {
// create order
return nil
}
func (o *OrderCreator) deleteOrder(ctx context.Context) error {
// delete order
return nil
}
type PaymentCreator struct{}
func (p *PaymentCreator) Execute(ctx context.Context) error {
return p.createPayment(ctx)
}
func (p *PaymentCreator) Rollback(ctx context.Context) error {
return p.deletePayment(ctx)
}
func (p *PaymentCreator) createPayment(ctx context.Context) error {
// create payment
return nil
}
func (p *PaymentCreator) deletePayment(ctx context.Context) error {
// delete payment
return nil
}
type SagaManager struct {
actions []Saga
}
func (s *SagaManager) Execute(ctx context.Context) {
for i, action := range s.actions {
err := action.Execute(ctx)
if err != nil {
for j := 0; j < i; j++ {
err := s.actions[j].Rollback(ctx)
if err != nil {
// One of our compensation actions failed;
// by emitting a message to a a messagebus, we need to handle it
}
}
}
}
}위 코드는 Saga 패턴을 구현한 예시이다.
Saga 인터페이스는 Execute와 Rollback 메서드를 정의하며, 이를 충족시키는 OrderCreator와 PaymentCreator를 정의한다.
그리고 SagaManager는 Handle 메소드를 통해 이러한 작업들을 순서대로 실행하고, 롤백하는 역할을 한다.
Handle 메소드에서는 등록된 모든 작업을 순회하며 작업을 실행한다.
이 때 에러가 발생하면 이전에 수행한 작업을 모두 롤백한다.
이 예제에서는 롤백이 실패하는 경우 특정한 작업을 수행하지는 않지만, 엔지니어에게 알림을 보내거나 Message Bus를 통해 다른 시스템에 알림을 보내는 등의 작업을 수행할 수 있다.
Message Bus
메시지 버스의 종류는 다양하다. 가령 메시지 큐는 메시지 버스와는 조금 다른 느낌이기는 하지만, 메시지가 도착한 순서대로 처리된다는 특징이 있다. 그 외에도 Kafka, RabbitMQ, NATS 등 다양한 메시지 버스가 존재하며, 이들의 특징과 장단점에 대해 알아보려 한다.
Kafka
Apache Kafka는 Apache Software Foundation에서 개발한 오픈소스 메시지 버스이다. 원래 LinkedIn에서 개발되었고, 사용성이 다양하여 큰 인기를 얻었다. 또한 지연시간을 낮게, 오류에 대한 저항성을 높게 유지하면서도 수백만 개의 메시지를 처리할 수 있다.
일반적인 카프카의 아키텍처는 다음과 같다.
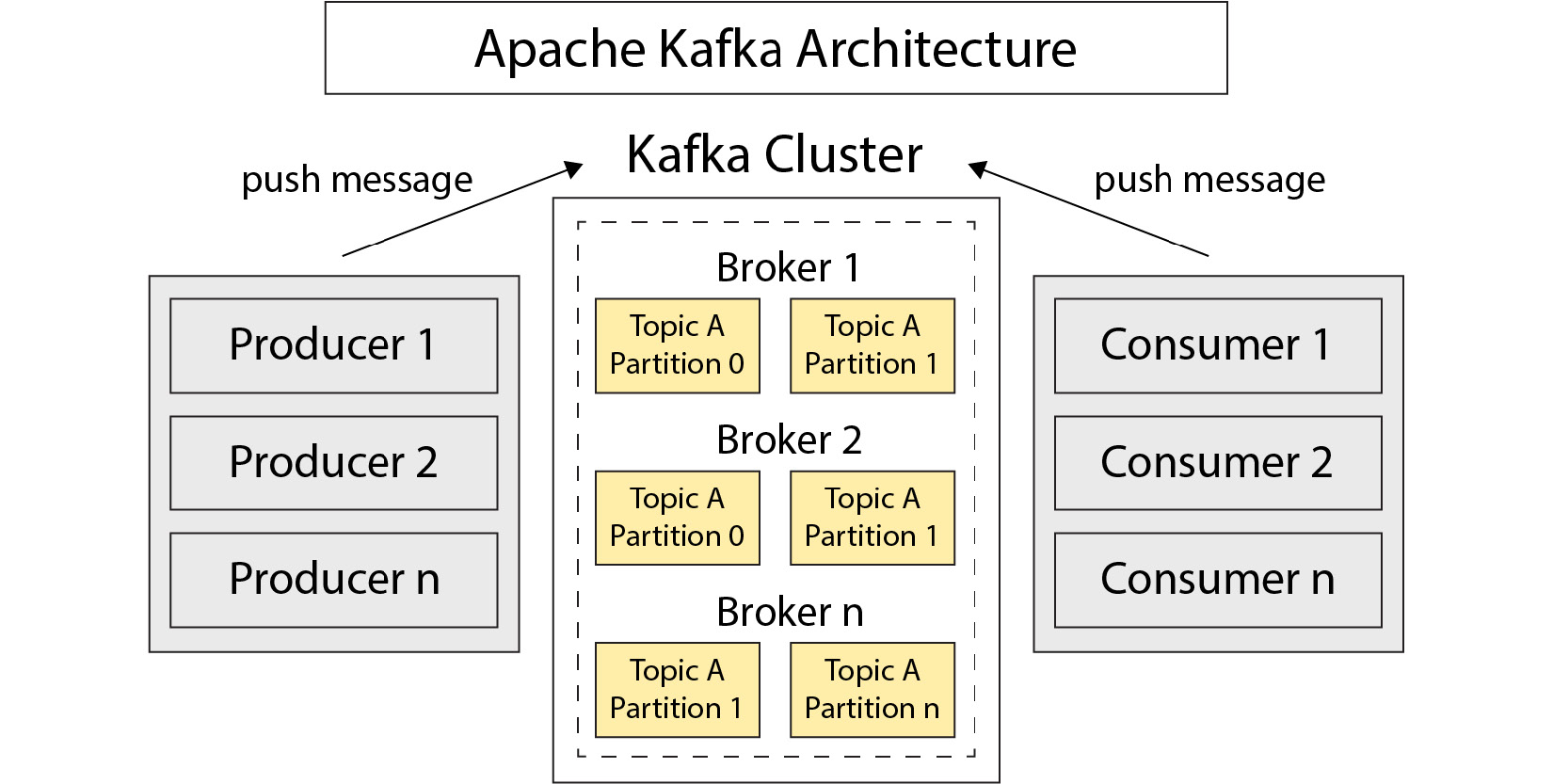
먼저 Broker는 Topic으로 전달된 메시지를 저장하며, Topic은 여러 파티션으로 분산될 수 있다. Producer는 Kafka에 연결하여 메시지를 전달하며, 메시지 대상, Topic, 그리고 파티션을 지정할 수 있다. Consumer는 Topic과 파티션을 Subscribe하여 메시지를 수신할 수 있다. 확장성을 위해 여러 개의 Consumer를 그룹화할 수 있으며, 이 소비자 그룹은 일치하는 Topic의 모든 메시지를 읽으며 함께 작동한다.
서비스는 Producer와 Consumer 둘 다 될 수 있다. 이를테면 어떤 서비스는 한 Topic의 메시지를 읽어 처리하고, 다른 서비스로 메시지를 보낼 수 있다.
Kafka의 문제점은 알아야 할 개념이 많다는 것이다. 또한 잘못 사용하면 애플리케이션에 치명적인 영향을 미칠 수 있다. 또한 모니터링이 어려울 수 있으며, 클러스터를 관리하는 것도 쉽지 않다.
RabbitMQ
RabbitMQ는 AMQP(Advanced Message Queuing Protocol) 기반의 오픈 소스 메시지 브로커이다. RabbitMQ에서 메시지는 Producer에 의해 exchange로 전달되며, 메시지는 라우팅 키에 하나 이상의 queue에 보내진다. queue에서 consume된 메시지는 또 다시 받을 수 없다.
이처럼 RabbitMQ는 개념적으로 간단하기 때문에 시작하기 쉽다. 또한 기본적으로 모니터링을 위한 UI를 제공한다는 장점이 있다. 하지만 Kafka처럼 쉽게 확장되지 않는다. 실질적으로 RabbitMQ는 Kafka가 제공하는 기능의 일부만을 지원하기 때문이다. 따라서 일반적으로 RabbitMQ를 사용하는 팀은 팀 규모나 소프트웨어 규모가 커짐에 따라 Kafka로 마이그레이션하는 경우가 많다.
NATS
NATS(Neural Autonomic Transport System)는 Golang으로 작성된 오프 소스 스트리밍 시스템이다.
NATS는 Topic에 메시지를 발행하고, Subscriber가 해당 Topic을 구독하여 메시지를 수신한다는 점에서 Kafka와 유사하다.
NATS는 *를 사용하는 와일드카드 일치를 지원하는 등 추가적인 기능을 제공한다.
하지만 NATS는 최대 1회 전달을 보장하기 때문에 메시지가 손실되는 경우가 발생할 수 있다. 대신 실행시키기가 매우 간단하며, 적은 리소스를 사용하고, 빠르다는 장점이 있어서 IoT와 같은 분야에서 많이 사용된다.
References
[
[Matthew Boyle, Domain-Driven Design with Golang』, O'Reilly Media, Inc.](https://learning.oreilly.com/library/view/domain-driven-design-with/9781804613450/)