Spark 논문(RDD) 정리
Abstraction
RDD(Resilient Distributed Datasets)
Resilient : 메모리 내부에서 데이터가 손실 시 유실된 파티션을 재연산해 복구할 수 있다.
Distributed : 스파크 클러스터를 통하여 메모리에 분산되어 저장된다.
Data : 파일, 정보 등등
- 분산 메모리 abstraction
- fault-tolerant하게 in-memory computation 가능해짐
iterative한 작업이나 interactive data mining 작업의 경우 in-memory로 하면 성능 향상
shared memory의 제약된 형태로 fine-grained보단 course-grained 사용함
Spark에서는 이 RDD를 사용하여 다양한 형태의 user application이나 computation에서 적용 가능
Introduce
MapReduce나 Dryad 등 데이터 분석 도구 특징
- fault tolerant나 work distribution에 대한 걱정 없이 High level operator를 통해 분산 환경에서 parallel computation 허용함
- 즉, 얘네들은 분산된 resource에 접근하는 abstraction임
- 근데 분산된 메모리를 활용하기 위한 abstraction은 부족함
data reuse 측면
- iterative한 작업(머신 러닝, 그래프 알고리즘 등)이나 interactive data mining 작업을 할 때, computation 사이에서 데이터를 reuse하는 유일한 방법은 intermediate data를 external stable storage에 저장하는 것임. (이런 애들은 reuse 자주 함)
- data replication, disk I/O, serialization 등 execution time 큰 것들로 인해 overhead 발생함
- intermediate data를 메모리에 저장해서 reuse하는, Pregel과 HaLoop이라는 애들이 나오긴 했음. 근데 얘네들은 오직 특정한 형태의 computation pattern만 지원함
- general하게 reuse할 수 있는 abstraction은 없음
RDD는 다양한 application에서 data reuse를 가능하게 함
- intermediate data를 메모리에 저장할 수 있는 fault tolerant, parallel 데이터 구조
- 최적화되게끔 partitioning을 제어하거나 다양한 operator를 사용해서 데이터를 조작할 수 있음.
- adhoc query를 돌릴 수도 있다.
기존에 존재하는 클러스터 단위의 in-memory storage abstraction(distributed shared memory, key-value store, database, Piccolo)는 mutable state를 fine grade로 나누었음(ex. cells in table)
- 이런 방식에서 fault-tolerance를 제공하려면 machine들 사이에서 1. replication을 저장하거나, 2. log update를 해야 함.
- 이러한 방식은 상당한 양의 data-intensive workload가 발생하며, 데이터들이 cluster network를 통해 복사됨. cluster network의 bandwidth는 RAM보다 훨씬 별로라서, overhead가 발생함
반면 RDD에서는 이런 시스템과는 달리, 많은 데이터 항목에 동일하게 operation을 적용 가능한 course-grained 기반의 정보 교환(map, filter, join 등)을 함
- 실제 데이터가 아닌, dataset(lineage)을 만들 때 사용되는 transformation을 logging함으로써, fault tolerance 제공
- lineage chain이 점점 커지면 데이터 자체를 checkpointing하는 게 유용할 때도 있음
- 만약 RDD의 partition을 손실한다고 해도, RDD에서는 그 partition이 다른 RDD로부터 어떻게 생겨났는지에 대한 정보를 가지고 있음. 따라서 그 파티션을 recompute함
- 따라서 손실된 데이터는 (비싼 data replication을 하지 않고도) 빠르게 복구될 수 있음
coarse-grained transformation 기반의 인터페이스가 처음에는 너무 제약된 형태로 보일 순 있지만, RDD는 다양한 병렬 application에 적합함.
- 이러한 application은 여러 data item에 동일한 operation을 적용하는 경향
- 실제로, RDD는 MapReduce, Dryad, SQL, pregel, HaLoop 뿐만 아니라, 이러한 시스템으로 하기 어려운 interactive data mining과 같이 새로운 application 등, 분리된 시스템으로 제안된 cluster programming model에 적용될 수 있음
Spark라는 시스템에 RDD 구현하였음
- UC 버클리를 비롯한 여러 회사에서 연구 및 production에 사용중
- Spark는 language-intergrated programming interface를 제공함(언어 자체에 Query문이 포함된 LINQ처럼). 또한 Spark는 Scala interpreter를 통해서 크기가 큰 dataset에 query를 날릴 수 있음
Spark의 성능
- iterative application에서 하둡보다 20배 빠르고, real-world data analytic report에서 40배 빠르고, 1TB dataset을 scan하는 데 5~7초가 걸린다.
- RDD의 generality(범용성)을 증명하기 위해, Pregel과 HaLoop의 프로그래밍 모델을 Spark 위에서 구현하기도 했음. 이때 Pregel과 HaLoop이 사용하는 placement optimization을 적용하였고, 비교적 적은 라이브러리로 구현함.
Resilient Distributed Datasets(RDD)
RDD Abstraction
RDD는 Read-only이며, record들의 Partitioned Collection임.
- RDD는 stable storage의 데이터나, 다른 RDD에 대한 deterministic operation을 통해서만 생성될 수 있음.
- deterministic : 예측한 그대로 동작. 어떤 특정한 입력이 들어오면 언제나 똑같은 과정을 거쳐서 언제나 똑같은 결과를 내놓는다.
- 이러한 operation을 RDD의 다른 operation과 구분하기 위해 transform이라 부름. transform의 예는 map, filter, join 등이 있음
RDD는 항상 materialized일 필요는 없음(구체적으로 모든 정보를 포함할 필요는 없음).
- 대신 stable storage에 저장된 데이터의 partition을 계산하기 위해, 다른 dataset(lineage)으로부터 어떻게 만들어진 것인지에 대해 정보를 포함하고 있음
- 프로그램은 failure가 발생한 후 reconstruct할 수 없는 RDD를 참조할 수 없음
사용자는 RDD의 persistence(지속성)과 partitioning을 조절할 수 있음.
- 재사용할 RDD를 지정하고, 어떤 storage strategy를 사용할 것인지 결정 가능 (ex. in-memory storage)
- 또한 RDD element가 각 record의 key에 따라 machine별로 partition 되게끔 요청할 수 있음
- 이는 placement optimization할 때 유용
Spark Programming Interface
Spark는 laguage-integrated API를 통해 RDD를 제공함
- DryadLINQ나 FlumeJava와 유사함. 여기서는 각각의 dataset이 object로 표현되고, method를 통해 transformation을 호출함
개발자들은 stable storage로부터 (map이나 filter 등의)transformation을 함으로써, 한 개 이상의 RDD를 정의할 수 있음.
- 이렇게 RDD를 얻으면, action을 취할 수 있음
- action : 그 값을 applciation으로 반환하거나, storage system 밖으로 데이터를 빼내는 등으로 사용하는 것. action의 예는 다음과 같음
- count : dataset 내의 element의 수
- collect : element 자체를 반환
- save : dataset을 storage system에 저장
- Spark는 RDD에서 처음 실행되는 action을 느리게 연산하여, transformation에 pipeline할 수 있음
persist : 특정 RDD가 미래의 operation에서 reuse될 수 있게끔 지정하는 method
- Spark는 default로 persistent RDD를 메모리에 저장해둠
- 하지만 RAM에 공간이 없으면 disk로 spill할 수 있음
- 유저 또한 다른 persistence strategy를 요청할 수 있음. 예를 들면 persist라는 flag는 RDD를 disk에만 저장하거나, 다른 machine들에 replication을 저장함
- 유저는 RDD별로 persistence priority를 지정하여, 어떤 in-memory data가 disk로 먼저 spill되게끔 할 것인지 결정할 수 있음
Example: Console Log Mining
웹 서비스가 장애를 겪고 있고, 오퍼레이터가 원인을 찾아내기 위해 테라바이트 단위의 로그를 HDFS로 분석해 본다고 가정해봅시다.
- Spark를 쓰면 오페레이터는 log의 에러 메시지를 RAM으로 불러와서, interactively(대화식) query를 날릴 수 있다.
 - line 1 : HDFS 파일으로부터 RDD를 정의한다
- line 2 : 1의 RDD에서 Filter된 RDD (ERROR로 시작하는 데이터) => scala 문법으로 가능!
- line 3 : *errors*라는 RDD가 메모리에 남아서, query 사이에서 공유될 수 있게 함
- line 1 : HDFS 파일으로부터 RDD를 정의한다
- line 2 : 1의 RDD에서 Filter된 RDD (ERROR로 시작하는 데이터) => scala 문법으로 가능!
- line 3 : *errors*라는 RDD가 메모리에 남아서, query 사이에서 공유될 수 있게 함
cluster에 수행될 작업이 없다면, RDD로 에러 메시지의 수를 세는 등, action을 할 수 있음.

사용자는 이렇게 얻은 RDD에서 추가적인 transformation을 실행하고, 그렇게 또 얻은 RDD에서 결과를 얻을 수 있음

errors에 관련된 첫 번째 액션(위에선 count)이 실행되면, Spark는 errors의 partition을 메모리에 불러옴. 그러면 다음의 매우 연산이 빨라짐
- 이때 lines라는 RDD를 메모리로 불러오는 게 아님! count라는 action이 처음 수행된 *errors*를 메모리로 불러옴! (Lazy Execution)
- 에러 메시지는 데이터의 극히 일부분에 해당하는 것이기에 충분히 작음. 메모리에 올려도 괜찮음
이 모델이 fault tolerance를 달성하는 방법을 그림으로 나타낸 것
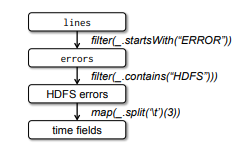
- 위 3개의 query에 대한, RDD의 lineage graph
- lines라는 RDD에 대한 filter의 결과로, errors라는 RDD를 얻음
- 1에서 filter하여 다음의 RDD, map 하여 다음의 RDD를 얻음
- 2에서 collect()
- Spark의 스케쥴러는 2의 map, filter 변환을 파이프라인화함
- errors라는 RDD의 데이터가 캐싱되어 있는 partition을 가진 node한테 연산하라고 던짐 (아까 errors는 count() 했었죠? 메모리에 올라가 있음)
- 만약 partition을 손실할 경우, Spark는 해당되는 line 파티션에만 filter를 적용하여 재구성함
Advantages of the RDD Model
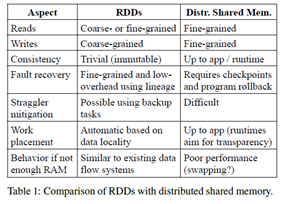
RDD와 Distributed Shared Memory(DSM)를 비교했을 때 장점이 나옴.
- DSM은 global address space의 임의의 공간에서 read/write를 수행
- 전통적인 shared memory system 뿐 아니라, Piccolo나 분산 데이터베이스 등 shared state를 fine-grained로 write하는 application도 DHT 사용함
- DSM은 일반적인 방식이지만, 하지만 이런 방식은 commodity cluster에서 효율적이고 fault-tolerant한 방식으로 구현하기 어려움
- DSM은 각 메모리의 위치별 read / write를 허용하지만(이게 fine-grained의 정의임. 그리고 RDD도 read 연산은 fine-grained로 가능함), 반면 RDD는 Course-grained인 transformation을 통해서만 생성(write)될 수 있음
- 이는 RDD를 사용하는 application이 bulk write만 하게끔 제약하지만, 보다 효율적인 fault-tolerance를 제공함
- RDD는 checkpointing의 overhead가 없는 대신, lineage를 통해 회복이 가능. (물론 lineage chain이 너무 길 경우 체크포인트를 쓰기도 함. 나중에 다룰 예정)
- 또한 RDD에서는 failure 발생 시 오직 손실된 partition만 복구하며, 이는 전체 프로그램을 rollback할 필요 없이 다른 node에서 병렬적으로 실행 가능함. RDD의 두 번째 장점은, straggler가 있으면 그 태스크의 백업 복사본을 실행할 수 있다는 것(MapReduce처럼)
- DSM에서는 Backup Task를 만드는 것이 어려움. 두 task가 동일한 메모리 영역을 액세스하여, 설의 업데이트를 방해하는 등 문제가 생길 수 있기 때문임.
마지막으로, RDD는 두 가지 이점을 제공함
- bulk 연산에서 data locality에 따라 runtime schedule 가능 => 성능 향상
- 스캔 기반 작업에만 사용된다면, 저장할 공간이 없을 때 성능 저하가 graceful하게 일어남.
- RAM에 맞지 않는 partition은 disk에 저장되며, 현재의 data-parallel system과 유사한 성능을 냄.
Application Not Suitable for RDDs
RDD는 same operation을 전체 dataset에 적용하는 batch application에 적합함
- RDD는 각 단계의 transformation을 lineage graph의 한 단계로 기억하며, 많은 양의 데이터를 기록할 필요 없이 손실된 partition을 복구할 수 있음.
반면 부적합한 application도 존재함
- asynchronous하게 fine-grained shared state를 update하는 application
- web server의 storage system
- 점진적인 web crawler
- 이러한 Application의 경우, 전통적인 log update, data checkpoint를 생성하는, database를 사용하는 것이 좋음
- Spark의 목표는 batch analytic을 위한 프로그래밍 모델을 제공하는 것
Spark Programming Interfaces
Spark는 language-integrated API를 통해 RDD abstraction을 제공함
- 함수형 + 정적 타이핑 언어인 Scala를 선택하였는데, 간결하기 때문에 interactive하게 사용하기 용이함
Spark를 쓰는 개발자는 driver program을 작성해야 하는데, 얘가 클러스터의 worker들에 접속함.
- Driver는 한 개 이상의 RDD를 정의하고, action을 호출함.
- Driver는 RDD Lineage를 추적함
- worker는 여러 연산을 통해 RDD Partition을 RAM에 저장할 수 있는 long-lived process임
map과 같은 RDD Operation에는 closure(function literal)를 넘겨줘야 함
- 이때 closure는 Java object로 표현되며, Serialize하여 네트워크를 통해 closure를 전송할 수 있음
- 또한, 이 closure에 묶여 있는 변수는 Object의 field값으로 설정됨
RDD 자체는 원소의 타입을 파라미터로 넘길 수 있는 statically typed objected이다.
- RDD[Int]는 Int의 RDD이다.
- Scala는 Type Interface를 지원하니, 타입을 생략해도 된다.
RDD Operations in Spark
 위 표는 Spark에서 사용 가능한 Transformation과 Action의 목록임.
위 표는 Spark에서 사용 가능한 Transformation과 Action의 목록임. - 대괄호 안에 타입 파라미터를 표시하여, 각 연산의 특징을 제시하였음.
- transformation은 lazy operation인 반면, action은 프로그램에 값을 반환하거나 외부 스토리지에 값을 write하기 위해 연산을 시작함.
join 등의 연산은 key-value pair 형태의 RDD에서만 가능함. 또한 함수 이름은 스칼라나 다른 함수형 언어의 API와 매칭이 가능하게끔 선정하였음
- map : 1-1 mapping / flatMap : MapReduce의 map과 유사함. 각 input value를 한 개 이상의 output과 mapping
사용자는 RDD가 지속되게끔 요청할 수 있음. (persist) RDD의 partition order를 얻을 수도 있음.
- Partitioner Class가 partition order를 나타냄. 이걸 가지고 다른 dataset을 partition할 수도 있음. groupByKey, reduceByKey, sort 등의 연산은 자동으로 hash partition 또는 range partition된 RDD를 생성한다.
Example: Logistic Regression
기계 학습 알고리즘의 경우, iterative한 경우가 많다.
- gradient descent 등 반복 최적화 절차를 수행하기 때문
- 따라서 데이터를 메모리에 저장한다면 험청 빨라질 것임
 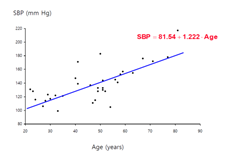
위 코드는 logistic regression 예제인데, 제가 머신러닝 이런거 안해봐서 뭔지 잘 모름 ㅈㅅ; 흐름만 봄
- text file에서 map
- parsePoint 함수 넘겨서 텍스트 파일의 각 라인으로부터 좌표상의 위치 얻음 => points
- 반복적으로 points에서 map 및 reduce하여 결과(w 벡터)를 얻을 수 있음
- 메모리에 올려놓고 반복하기 때문에 20배까지 속도가 빨라짐
Example: PageRank
- RDD의 partitioning을 사용하여, 성능을 향상시킬 수 있는 것을 보여줌
더 복잡한 data sharing pattern임. PageRank 알고리즘은 다른 문서에서 각 문서로 link되는 회수를 합산하여, 문서의 rank를 반복적으로 업데이트한다.
- 각 iteration마다 각 문서는 r/n의 기여도를 이웃들에게 보낸다. (r : rank, n : 이웃의 수)
- 그 후 순위를 α/N + (1 − α)∑ci 로 계산 (∑ci : 받은 기여도의 총합, N : 총 문서 수)
PageRank를 Spark로 나타내면 다음과 같음
 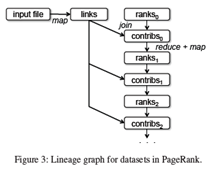 좌측의 프로그램을 돌리면 우측의 그림과 같은 RDD Lineage 그래프를 얻을 수 있음
좌측의 프로그램을 돌리면 우측의 그림과 같은 RDD Lineage 그래프를 얻을 수 있음 - 각 iteration마다, 이전 iteration의 contribs와 ranks, 그리고 정적인 links라는 dataset으로부터, 새로운 ranks라는 dataset을 만듦.
- 이 그래프의 흥미로운 특징은, 반복의 회수만큼 graph가 늘어난다는 것이다.
- 이 작업은 많은 iteration이 동반되므로, fault recovery를 효율적으로 하려면 특정 버전의 ranks를 replication을 만들어서 저장해야 할 수도 있음
- 사용자는 RELIABLE 플래그를 줘서 persist 메소드를 호출하면 그렇게 할 수 있음
- 하지만 links라는 dataset은 replication을 만들 필요가 없음. 그냥 input file에서 map 다시 돌리면 해당 partition을 다시 얻는 게 더 효율적이기 때문
- 이 dataset은 보통 ranks보다 훨씬 크기가 큼. 각 문서에는 많은 링크가 있지만 순위는 한 개뿐이기 때문
- 따라서 lineage를 사용하여 복구하는 게, 프로그램의 전체 in-memory state의 checkpoint를 만드는 것보다 시간을 절약할 수 있음
RDD의 partitioning을 제어함으로써, PageRank 알고리즘에서의 통신을 최적화할 수 있음
- 만약 links를 기준으로 partitioning하게끔 명시한다면, ranks에 대해서도 동일한 방식으로 partitioning할 수 있음
- 그렇게 되면 links와 ranks간의 join 연산이 통신을 필요로 하지 않게 됨(같은 머신 위에 필요한 데이터가 있음)
- Partitioner class를 작성하여, 도메인 이름에 따라 페이지를 묶을 수도 있음.
- 아래와 같이, links를 정의할 때 PartitionBy()라는 method를 통해 진행

- RDD는 사용자가 이러한 목표(일관된 partitioning을 통한 최적화)를 직접 표현할 수 있게 함.
Representing RDDs
RDD를 Abstraction으로 제공하기 위한 과제 중 하나는, 광범위한 transformation에서 lineage를 추적할 수 있는 표현을 선택하는 것임
- RDD를 구현하는 시스템은 반드시 다양한 transformation 연산자들을 제공해야 하며, 사용자가 임의의 방식으로 transformation을 선택할 수 있게 해야 함.
- 이 논문에서는 graph-based의 표현을 제안함
- Spark에서는 이 표현을 사용함으로써, 각각의 스케줄러에 특별한 논리를 추가하지 않고 광범위한 transformation을 지원함
- 시스템 설계가 매우 단순화됨
각각의 RDD는 아래와 같은 정보를 노출하는 공통적인 인터페이스로 나타낼 수 있음
- partition의 집합 (dataset의 atomic pieces)
- Parent RDD에 대한 종속성(dependency) 집합
- Parent RDD를 기반으로 dataset을 계산하는 함수
- partitioning scheme 및 데이터 배치에 대한 메타데이터
- 해당 인터페이스는 아래와 같은 테이블에서 보여줌
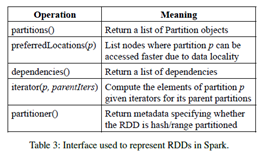
- 예를 들면, HDFS 파일을 표현하는 RDD는 파일의 각 블록마다 partition을 가지고 있고 어떤 machine의 블록에 올라가 있는지 정보를 알고 있음
- 한편 이 RDD에 map을 한 결과물은 동일한 partition을 가지지만, 요소를 계산할 때 parent data에 map 함수를 적용한다.
- 해당 인터페이스는 아래와 같은 테이블에서 보여줌
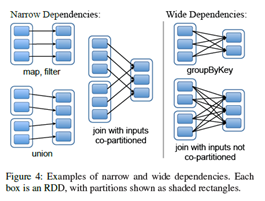 RDD간의 종속성(Dependency)를 나타내는 인터페이스는 두 종류가 있음
RDD간의 종속성(Dependency)를 나타내는 인터페이스는 두 종류가 있음 - narrow dependency: 1개의 Parent RDD에 1개의 Child RDD가 종속
- wide dependency : 1개의 Parent RDD에 여러 개의 Child RDD가 종속될 수 있음
- 예를 들어 map은 narrow dependency이고, join은 (parent가 hash-partitioned 되어있는 게 아니라면) wide dependency임.
이렇게 narrow와 wide로 구분하는 게 유용한 이유가 두 가지 있음.
narrow dependency는 모든 parent partition을 계산할 수 있는 하나의 cluster node에서 pipelined execution이 가능함. => 예를 들면 각 요소마다 filter 이후 map을 적용할 수 있음 => 반면 wide dependency에서는, MapReduce처럼 Parent Patrtition의 모든 데이터가 Child들에 Shuffle되어야 한다.
node failure 이후 회복할 때는 narrow dependency에서 더 효율적임 => 손실이 발생한 parent partition만 회복하면 되기 때문이며, 이는 다른 노드에서 병렬적으로 재연산이 가능 => 반면 wide dependency의 lineage graph에서는, 특정 단일 노드에서 failure가 발생하면 해당 RDD의 조상으로부터 형성된 특정 파티션을 잃어버릴 수도 있으며, 이 경우 완전히 재실행해야 할 수도 있음.
Spark에서, 이러한 RDD의 공통적인 인터페이스는 대부분의 transformation을 20줄 이내로 수행할 수 있게 하였음. 아래 내용은 여러 RDD 구현이 요약된 것임
HDFS Files
- RDD가 HDFS의 파일인 경우, partitions()는 파일의 각 블록당 한 개의 partition이 반환된다.
- 각 Partition 객체에 block offset이 포함되어 있다
- prefferedLocation()은 블록이 존재하는 노드를 반환한다.
- iterator()는 블록을 읽는다.
map
- 임의의 RDD에서 map을 호출하면 MappedRDD 객체가 반환된다
- 이 객체는 parent와 동일한 partition 및 preferred location을 가지지만, Iterator()는 parent의 record와 매핑하기 위해 전달된 함수를 적용한다.
union
- 두 개의 RDD에서 union을 호출하면, 각 부모의 partition이 합쳐진 partition을 가진 RDD가 반환됨
- 각각의 Child Partition은 parent에 대한 narrow dependency를 통해 계산됨
sample
- sample은 map과 비슷하지만, RDD가 parent record를 deterministically하게 샘플링하기 위해 각 partition마다 random number seed를 저장한다는 차이가 있음
join
- 두 RDD를 join하는 연산은 세 가지 경우가 있음.
- 두 RDD가 동일 partition에 hash/range partition된 경우(partitioner가 같은 경우), 둘 다 narrow dependency
- 둘 중 하나만 hash/range partition된 경우(partitioner를 가짐), narrow와 wide 혼합
- 아니면, 둘 다 wide dependency임
- 어떤 경우이든 결과물인 RDD는 partitioner를 가지며, parent로부터 물려받거나 default hash partitioner를 가짐
Implementation
Spark 시스템은 Mesos cluster manager 위에서 동작하며, Hadoop, MPI(Message Passing Interface) 등 다른 어플리케이션과 리소스를 공유할 수 있다.
- 각각의 Spark 프로그램은 driver(master)와 worker를 가진 별도의 Mesos Application으로 동작한다.
- 애플리케이션 간의 자원 관리는 Mesos에 의해 처리된다.
Spark는 HDFS, HBase 등 Hadoop의 입력 소스를 통해 데이터를 읽어올 수 있다.
- 기존의 Hadoop에서 사용하는 input plugin API를 사용한다.
- 특별히 수정된 Scala 버전을 사용하지 않아도 된다.
Job Scheduling
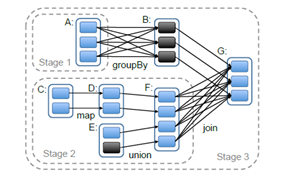 그림에서 검정색은 이미 메모리에 올라가 있는 부분임.
stage 1의 결과물이 이미 RAM에 올라가 있으므로, stage 3의 RDD를 얻기 위해서는 stage 2, 3만 하면 됨
그림에서 검정색은 이미 메모리에 올라가 있는 부분임.
stage 1의 결과물이 이미 RAM에 올라가 있으므로, stage 3의 RDD를 얻기 위해서는 stage 2, 3만 하면 됨 Spark scheduler는 4장에서 다루었던 RDD 표현을 사용한다. Spark의 scheduler는 Dryad의 scheduler와 비슷하지만, persistent RDD의 어떤 partition을 메모리에 올릴지도 고려한다.
- 위 그림처럼, 유저가 RDD에 대한 action을 수행할 때마다 scheduler는 실행할 stage의 DAG를 만들기 위해 RDD의 lineage graph를 검사한다.
- DAG : Directed Acyclic Graph. Cycle이 없는 Directed Graph
- 각 stage는 narrow dependency로 구성할 수 있는, 여러 transform의 파이프라인으로 구성되어 있음
- 각 stage를 구분하는 것은 wide dependency에 필요한 shuffle 연산 또는 parent RDD의 계산을 단순화할 수 있는 이미 계산된 partition이다.
- Scheduler는 대상 RDD가 계산될 때까지, 각 stage의 missing partition을 연산하는 작업을 생성한다.
Spark의 scheduler는 delay scheduling을 사용하여, data locality에 따라 machine에 작업 할당
- 만약 task가 어느 노드의 메모리에서 사용 가능한 partition을 처리해야 할 경우, 해당 노드로 보낸다.
- 또는 task가 HDFS처럼 preferred location이 존재하는 RDD의 partition을 처리하는 경우, 해당 파티션으로 보냄 Wide Dependency(shuffle)의 경우, 오류 복구를 단순화하기 위해 parent partition을 보유한 노드에 있는 intermediate record를 materialize함.
- MapReduce가 map output을 materialize하는 것과 유사
- 만약 task가 failure하면, 해당 stage의 parent가 살아있는 한 다른 node에서 작업을 다시 실행함.
- 만약 특정 stage 자체를 사용할 수 없는 경우(예를 들면 shuffle 중 map side의 출력값이 손실된 경우), 병렬적으로 missing partition을 계산하기 위해 task를 다시 전송한다.
- RDD linage graph를 replicating하는 것은 간단하지만, scheduler 실패는 아직 핸들링하기 어려움
Spark의 모든 연산은 driver 프로그램에서 action이 호출되면 그에 따라 실행됨
- 하지만 map과 같은 cluster의 작업이 조회 작업을 호출하도록 하여, hash-partition된 RDD의 요소에 key값을 통해 random access할 수 있게 하는 실험도 하고 있음
- 이 경우, task는 scheduler에게 필요한 partition이 missing 상태일 경우 이를 계산하게끔 지시해야 함.
Interpreter Integration
Scala는 Python이나 Ruby처럼 interactive shell을 제공함
- 데이터를 in-memory로 처리하여 latency가 낮기 때문에, 사용자는 Spark Interpreter를 통해 interactive하게 많은 양의 데이터에 query를 날릴 수 있음
Scala interpreter는 사용가 입력한 클래스가 있는 라인을 컴파일하여 JVM에 로드하고, 그 위에서 함수를 호출함.
- 이러한 클래스는 그 라인에서 선언된 변수나 함수를 포함하며, initialize method로 그 라인을 실행하는 singleton object를 포함함.
- singleton object : class의 instance가 오직 1개만 생성됨
- 예를 들면, 만약 유저가 var x = 5를 입력하고 그 다음 println(x)를 입력했다고 가정
- 인터프리터는 x를 포함하는 Line1이라는 클래스를 만들고, println(Line1.getInstance().x)로 컴파일
Spark interpreter에서는 두 가지의 변화를 줬음
- Class Shipping: worker 노드가 각 라인에 선언된 클래스의 바이트 코드를 읽어올 수 있게끔, interpreter는 이런 클래스를 HTTP로 전송함.
- 수정된 코드 생성: 일반적으로 코드의 각 라인마다 생성된 Singleton Object는 해당 클래스의 static method를 통해 접근함.
- 위 예제(Line1.getInstance().x)처럼 이전 라인에서 정의된 변수를 참조하는 closure를 serialize할 때, Java는 object graph를 추적하여 x를 감싸는 Line1 인스턴스를 전달하지 않음. 따라서 worker 노드는 x를 받지 않을 것임.
- code generation logic을 수정하여, 참조를 하려고 할 시 각 라인의 object의 instance를 직접 참조하게끔 변경하였음
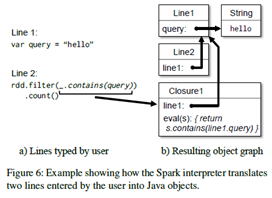 위 그림은 사용자가 입력한 라인을 interpreter가 어떻게 해석하는지 보여줌
위 그림은 사용자가 입력한 라인을 interpreter가 어떻게 해석하는지 보여줌 Spark interpreter를 쓰면 HDFS에 저장된 dataset을 탐색하거나, trace를 추적(아마 lineage graph?)하는데 유용하다는 것을 발견하였음.
Memory Management
Spark는 persistent RDD를 저장하기 위한 세 가지 옵션을 제공한다.
- in-memory storage - deserialized Java object
- JVM이 RDD 요소를 native하게 접근할 수 있기 때문에 가장 빠름
- in-memory storage – serialized data
- Java의 object graph보다 메모리 측면에서는 효율적이지만, 성능은 감소
- on-disk storage
- RDD가 너무 커서 RAM에 저장하기엔 너무 크지만 사용할 때마다 재계산하기에는 비용이 너무 많이 드는 RDD에 유용함
사용 가능한 메모리는 제한적이므로, RDD 레벨에서 LRU 제거 정책을 사용함.
- 새로운 RDD Partition이 계산될 때 이를 저장할 공간이 충분치 않다면, 가장 예전에 access된 RDD를 쫓아냄.
- 예외적으로, 새로운 partition이 있는 RDD와 동일한 RDD는 쫓아내지 않는데, cycling partition이 일어나지 않게끔 하기 위함
- 대부분의 작업은 RDD 전체에서 수행되기 때문에, 이는 굉장히 중요함. 이미 메모리에 있는 파티션이 미래에 필요할 가능성이 높음.
- 메모리 관리 정책의 기본값인 이 방식도 잘 동작하지만, 사용자는 각 RDD에 persistence priority를 부여하여 제어할 수도 있음.
Support for Checkpointing
RDD가 failure한 이후 lineage를 통해 복구할 수 있지만, lineage chain이 너무 길면 복구 과정에서 시간이 너무 오래 걸릴 수 있음
- RDD를 stable storage에 checkpointing하면 유용함
일반적으로 Checkpoint는 wide dependency를 포함하는, 긴 lineage graph의 RDD에 대해 유용함
- 만약 이 경우 클러스터 안의 노드의 falilure는 각각의 parent RDD로부터 온 데이터 조각의 손실로 이어질 수 있음. 이 경우 모든 데이터를 다시 계산해야 함
- 반면 narrow dependency의 경우에는, Checkpointing이 불필요함.
- 노드가 실패하여 lost partition을 계산하려면 전체 RDD를 복제하는 비용의 극히 일부만으로 다른 노드에서 병렬적으로 재계산할 수 있기 때문
Spark는 (persist() method의 REPLICATE flag 등) checkpointing API를 제공함.
- 다만 어떤 데이터를 checkpointing할지는 유저가 결정
- 시스템 복구 시간을 최소화할 수 있도록 자동으로 checkpointing하는 방법을 연구 중에 있음
RDD의 read-only라는 특성 덕에 일반적인 shared memory보다 checkpointing하기 쉬움.
- data consistency를 고려할 필요가 없음
- checkpointing을 background에서 진행하면서, 작동중인 프로그램을 멈추거나 특별한 분산 스냅샷 스키마를 사용할 필요가 없음. (동시에 가능)
Evaluation
EC2에 올려서 Spark와 RDD, 및 이를 사용하는 User Application의 성능을 검사하였음
- 스파크는 반복적인 기계 학습 및 그래프 애플리케이션에서 하둡을 최대 20배 능가함
- 데이터를 자바 객체로 메모리에 저장함으로써 입출력 및 역직렬화 비용을 피할 수 있기 때문에 속도가 향상된다.
- 사용자가 작성한 애플리케이션에 올라간 Spark는 성능과 확장성이 뛰어나다.
- analytics report 할 때 하둡보다 40배 빨랐음
- 노드에 장애가 발생하면 스파크는 손실된 RDD 파티션만 재구성하여 신속하게 복구할 수 있다.
- 스파크는 1TB 데이터 세트를 5-7초의 지연시간(latency)으로 대화식(interactively)으로 쿼리하는 데 사용할 수 있다
Iterative Machine Learning Applications
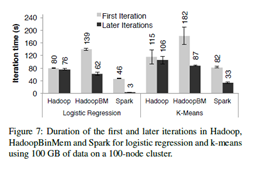 
- Logistic Regression: I/O 및 serialization sensitive
- K-Means: compute-intensive
- HadoopBinMem
- input data를 binary format으로 바꾸는 hadoop 버전
- 데이터를 in-memory HDFS 인스턴스에 저장
그림 7의 First iteration: HadoopBM > Hadoop > Spark
- HadoopBM : 데이터를 binary로 바꾸는 추가적인 작업 및 in-memory HDFS를 replicate하는 overhead로 인해 가장 느림
- Hadoop : heartbeat를 보내기 위한 Signaling overhead로 인해 Spark보다 느림
- Spark: 이후의 Iteration부터는 RDD로 인해 데이터가 reuse되어 빨라짐
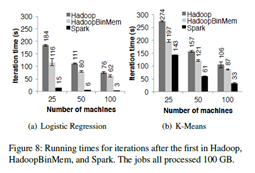
그림 8: 그냥 machine 수 달리해서 재 본거임. 역시 spark가 제일 빠름
하둡이 느린 이유
- 하둡의 소프트웨어 스택의 오버헤드 => 하둡은 job을 수행할 때 job 설정, task 시작, 정리 등의 overhead 등으로 인해, 최소 25초의 오버헤드가 발생
- 데이터를 서빙할 때 HDFS의 오버헤드 => HDFS는 여러 개의 메모리 복사본을 각 블록에 전송하며, 각 블록에 체크섬을 수행하기 때문에 오버헤드 발생
- binary record를 Java object로 변경하기 위한 deserialization 비용
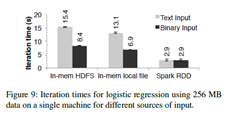 Text – binary 시간 차이 : parsing에 소요되는 시간
Text – binary 시간 차이 : parsing에 소요되는 시간 - Hadoop은 binary data를 Java object로 변환하는데 시간이 필요함
- Spark는 RDD 요소를 메모리에 Java object로 바로 저장하므로, 오버헤드를 회피함
PageRank
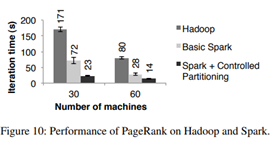 PageRank에서도 Spark가 빠르게 나옴
PageRank에서도 Spark가 빠르게 나옴 - Controlled Partitioning을 해주면, data access가 일관되게 일어나기 때문에 속도를 향상시킬 수 있다
- 또한 Pregel에서 PageRank를 돌려도, Pregel은 추가적인 연산을 하기 때문에 Spark의 버전보다 4초정도 더 길게 나옴.
Fault Recovery
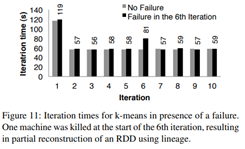 K-means를 돌릴 때 failure가 발생한 경우 recovery에 얼마나 시간이 걸리는지 보여줌
K-means를 돌릴 때 failure가 발생한 경우 recovery에 얼마나 시간이 걸리는지 보여줌 - 6번째 iteration에서 machine 하나 죽여서, 그 machine에서 돌아가는 task가 실패
- 다른 machone에서 task를 다시 실행
- 해당 task의 input data와 RDD lineage를 다시 읽고, RDD Partition을 재구성
checkpoint 기반의 장애 복구 메커니즘은 체크포인트 빈도에 따라 작업을 여러번 반복해야 할수도 있음
- 또한 시스템은 네트워크를 통해 대용량의 working set을 replicate해야 함
- 이를 RAM에 복제하면 Spark의 두 배 메모리를 쓰는 거고, DISK에 복제하면 대용량의 데이터를 쓰는 것을 기다려야 함
- Spark의 RDD lineage graph는 크기가 10kb 미만
Behavior with Insufficient Memory
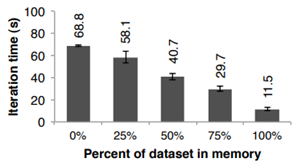 성능이 감소되긴 하지만 Graceful하게(어느정도 하락폭을 예측할 수 있게) 감소됨
성능이 감소되긴 하지만 Graceful하게(어느정도 하락폭을 예측할 수 있게) 감소됨 User Applications Built with Spark
In-memory Analytics:
- 영상 배포하는 Conviva Inc라는 회사는 analytic report를 만들기 위해 하둡을 쓰다가 Spark를 사용
- 40배 빨라짐
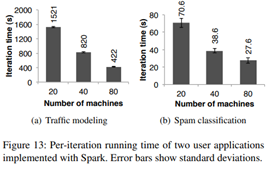
Traffic Modeling:
- 산발적으로 수집된 자동차 GPS 측정치에서 교통 현황을 추정하기 위한 학습 알고리즘을 병렬적으로 구성함.
- 두 개의 map과 reduceByKey를 반복적으로 적용하여 모델을 학습시켰고, 성능이 선형적으로 확장됨 (분산처리가 잘 되고 있음)
Twitter Spam Classification:
- 트위터의 스팸 메시지에서 link를 검증하기 위해 Spark 사용
- 앞서 봤던 logistic regression를 사용하였고, URL이 가리키는 페이지 정보를 수집함.
- 성능이 linear하게 늘어나지는 않았음 (communication cost가 iteration보다 높아지기 때문)
- 아마 네트워크에 접속해서 페이지 정보를 읽어와야 하기 때문인 듯
Interactive Data Mining
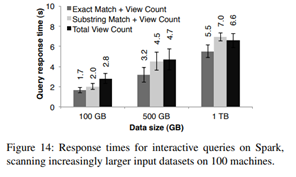 Spark는 거대한 dataset에 대화식 query를 날릴 수 있음
Spark는 거대한 dataset에 대화식 query를 날릴 수 있음 - (1) => 전체 페이지에 query하여 조회수 확인
- (2) => 제목이 주어진 단어와 같은 페이지만 조회수 확인
- (3) => 제목이 부분적으로 일치하는 페이지만 조회수 확인
- response time이 on-disk에서 하는 것보다 훨씬 빠름 (on-disk는 170초 걸렸다고 함)
Discussions
RDD는 immutable하고 coarse-grained transformation을 하므로, 제한된 interface만을 제공하는 것처럼 보이지만, 다양한 application에 적합함
Expressing Existing Programming Models
RDD는 지금까지 제안되어 온 다양한 클러스터 프로그래밍 모델을 “효율적으로” 표현할 수 있음
- 효율적이라는 말은, 단순히 이러한 모델로 작성한 프로그램과 동일한 output을 얻을 수 있을 뿐 아니라, 최적화까지 가능함.
- 데이터를 memory에 보관하고, communication을 minimize하기 위해 잘 partitioning하고, failure를 효율적으로 recovery함
RDD로 표현 가능한 모델
- MapReduce: flatMap, GroupByKey, reduceByKey가 각각 Mapper, Reducer, Combiner에 해당
- DryadLINQ: Spark로도 할 수 있음
- SQL: SQL query를 날려서 data-parallel operation을 수행할 수 있음
- Pregel: Google Pregel은 iterative graph application에 특화된 모델임
- RDD를 사용하면 Pregel이 하는 것처럼 vertex state를 메모리에 유지하고, Partitioning을 제어하고, 통신을 최소화하고, 장애 시 부분적인 복구를 수행할 수 있다.
Iterative MapReduce
- HaLoop 및 Twister 등 MapReduce를 Iterative하게 돌리기 위한 시스템이 있음
- 얘네의 핵심은 partitioning 및 메모리에 올려놓고 reuse하는 것인데, 이것도 Spark 200줄로 표현이 가능했음 Batched Stream Processing
- 새로운 데이터를 받아서 주기적으로 결과를 업데이트하는 점진적인 시스템
- Intermediate state를 RDD로 두면 처리 속도가 향상됨.
RDD가 이렇게 다양한 프로그래밍 모델을 표현할 수 있는 이유는, RDD의 제약조건이 다수의 병렬 어플리케이션에서 큰 의미가 없기 때문임.
- RDD는 오직 transformation을 거쳐서 생성될 수 있음
- 근데 대부분의 병렬 프로그램이 표현을 쉽게 하려고 원래 동일한 연산을 record에 적용하고 있음.
- 동일한 dataset의 버전을 나타내기 위해 여러 개의 RDD를 생성할 수 있기 때문에, RDD의 immutability는 장애물이 아님.
- 실제로, 대부분의 MapReduce 애플리케이션은 HDFS 등 파일 업데이트를 허용하지 않는 파일 시스템에서 실행됨.
이전 프레임워크들은 데이터 공유를 위한 abstraction이 부족했기 때문에 이런 범용성을 가지지 못한 것 같음
Leveraging RDDs for Debugging
DD는 fault tolerance를 위해 deterministical하게 다시 계산할 수 있게끔 설계되었지만, 이러한 특성 덕분에 디버깅도 잘함
- 작업 중 RDD의 lineage를 기록함으로써, RDD를 나중에 재구성하여 사용자가 대화식으로 query할 수 있고, RDD 종속된 파티션을 다시 계산하여 단일 프로세스 디버거에서 job의 모든 task를 다시 실행할 수 있음
여러 노드에서 이벤트 순서를 캡쳐해야 하는 기존의 general distributed system에서의 replay debugger와는 달리, 이 방식은 RDD lineage graph만을 기록하기 때문에 recording overhead가 거의 없음.
Related Work
Cluster Programming Models:
data flow model
- MapReduce, Dryad, Ciel 등은 데이터 프로세싱을 위한 다양한 Operator 제공
- 반면 RDD는 data replication, I/O 및 serization의 높은 비용을 피하기 위해 stable storage보다 더 효율적인 abstraction을 제공함.
High level programming interface for data flow system
- DryadLINQ, FlumeJava는 사용자가 map, join 등의 연산자로 parallel collection에 접근할 수 있는 language-integrated API를 제공
- 하지만 이러한 시스템들은 query의 결과를 다른 query로 pipeline하기 어려움
- Spark는 이것이 가능하기 때문에, 다양한 Application에서 활용할 수 있음
Pregel, HaLoop, Twister 등은 generic abstraction을 제공하지 않아서 정해진 용도 이외의 용도로 사용하기 어려움.
- RDD는 distributed storage abstraction을 제공하여, interactive data mining 등 위의 시스템이 하기 어려운 것도 가능함
Piccolo나 RAMCloud 등의 Distributed Shared Memory 기반의 시스템은 사용자가 in-memory computation을 수행할 수 있게끔, shared mutable state를 노출시킴.
- RDD는 두 가지 측면에서 이러한 시스템과 다름
- RDD는 map, sort, join 등 high level interface를 제공하는 반면, 위의 애들은 table cell에 대한 read/update밖에 지원하지 않음
- RDD는 Lineage based라서, 위 애들보다 checkpoint 및 rollback이 덜 무거움
Caching System:
Nectar는 DryadLINQ 작업에서 intermediate data를 재사용할 수 있음.
- RDD에서도 이러한 능력을 본땄음
- 근데 Nectar는 in-memory caching을 제공하지 않고, 사용자가 원하는 dataset을 persist 및 partitioning control하게끔 하는 기능이 없음.
- CIel 및 FlumeJava는 in-memory로 caching을 지원하지 않고, 원하는 데이터를 caching할 수 없음
- 분산 파일 시스템에 대한 인메모리 캐시도 제시되었지만, RDD처럼 중간 결과를 sharing하는 것보다는 약간 모자람
Lineage:
Lineage를 capture하는 것은 오랜 연구 주제였음.
- RDD는 fine-grained lineage를 capture하는 데 비용이 적게 드는 병렬 프로그래밍 모델을 제공하여, 장애 복구에 사용할 수 있도록 함.
- 이러한 lineage based의 회복 매커니즘은 MapReduce나 Dryad의 메커니즘하고 비슷하지만, 얘네들은 job이 끝나면 lineage를 잃어버리므로, 컴퓨팅 간에 데이터를 공유하려면 replicated storage를 사용해야 함
- 반면 RDD는 disk I/O나 replication 없이 lineage를 써서, 데이터가 메모리에 지속되게 하여 효율적으로 데이터를 공유할 수 있음.
Relational Database:
RDMS는 fine-grained이며 모든 record에 대한 read/write 접근을 허용함. 또한 fault tolerance, logging operation, consistency를 유지해야 함
- 반면 RDS는 coarse-grained이므로 이런거 할 필요가 없음
Conclusion
RDD : cluster application에서 데이터를 sharing하는 abstraction
- 효율적인, general-purpose, fault-tolerance를 제공
RDD는 다양한 종류의 병렬 application을 표현할 수 있음
- iterative computation을 위해 제안된 많은 특화된 프로그래밍 모델과, 이러한 모델이 캡처하지 못하는 새로운 응용 프로그램 등 다양한 병렬 애플리케이션을 표현할 수 있음.
fault tolerance를 위해 data replicating을 선택하는 기존 cluster의 storage abstraction과는 달리, RDD는 coarse-grained transformation 기반의 API를 제공
- lineage를 통해 효율적으로 recover 가능
RDD가 구현된 시스템인 Spark의 성능은 interactive application에서 Hadoop보다 20배 뛰어남. 또한 100기가바이트 대의 데이터에 대화형 쿼리를 날릴 수도 있다.