Distributed Counter
Netflix’s Distributed Counter Abstraction

을 하려 했는데, 이걸 읽으려면 Timeseries Data Abstraction을 먼저 봐야 한다…

하지만 읽었죠?
Introduction
이전의 Timeseries Data Abstraction을 이용하여 쌓아올린 분산 카운터 근데 이제 낮은 레이턴시를 곁들인
낮은 레이턴시로 최대한 정확한 분산 카운터를 만들기 위해 우리 넷플릭스 친구들은 이런 선택을 했답니다
Requirements
- Best effort 또는 Eventually Consistent 모드중 하나를 선택 가능해야 함
- Best effort는 코스트가 저렴하고 빠른 대신 근사치를 내놓음
- Eventually Consistent는 정확도를 위해 속도와 인프라 비용을 감수
레이턴시 낮췄다곤 하지만 서비스 로직에 쓴다는 얘긴 없네요
API
자바에 있는 AtomicInteger랑 비슷한 API라고 합니다. TTL, 카운터 타입, 카디날리티 등등 설정 가능
- AddCount
- AddAndGetCount
- GetCount
- ClearCount
modify 작업을 할 때마다 idempotency_token이 같이 날아옴
"idempotency_token": {
"token": "some_event_id",
"generation_time": "2024-10-05T14:48:00Z"
}Show⯆
요청을 hedging하거나 안전하게 재시도하기 위함
잼민아 hedging이 뭐야
Best Effort Regional Counter
- EVCached라고 하는 분산 캐시를 사용함 (Memcached 기반)
- 적당한 추정치 정도면 충분한 유즈케이스에 적합.
- 빠르고 인프라 비용이 적은 대신 cross region replication과 일관성을 보장하지 않아 정확하진 않음. 멱등성도 지원하지 않음
- 확률적 자료구조 안 썼음
- HyperLogLog는 개별 요소의 근사치를 처리하기 좋지만 특정 키의 증감을 처리하기엔 적절치 않음
- CMS(Count-Min Sketch)도 redis에서 지원하긴 함
- 근데 주어진 키에 대한 카운트 재설정, TTL 등을 할 수가 없음
- 원래 있던 거 쓰기로 한 대신 메모리는 더 많이 먹는데 감수하기로 함
Eventually Consistent Global Counter
- 좀 더 정확한 개수와 글로벌 가용성을 위해 선택할 수 있음
구현 방식과 접근들
- Approach 1: Storing a Single Row per Counter

- 멱등성도 없고 경합걸리면 성능 떨어져서 구리다
- 보조 키로 bucket_id같은 걸 둔다면? 분산된 카운터중 하나에만 write하고, 읽는 건 동시에 읽는다면?
- 그럼 카운터당 버킷 개수를 결정하는 게 문제가 된다. 괜찮은 방법이긴 한데 다른 방법도 보자
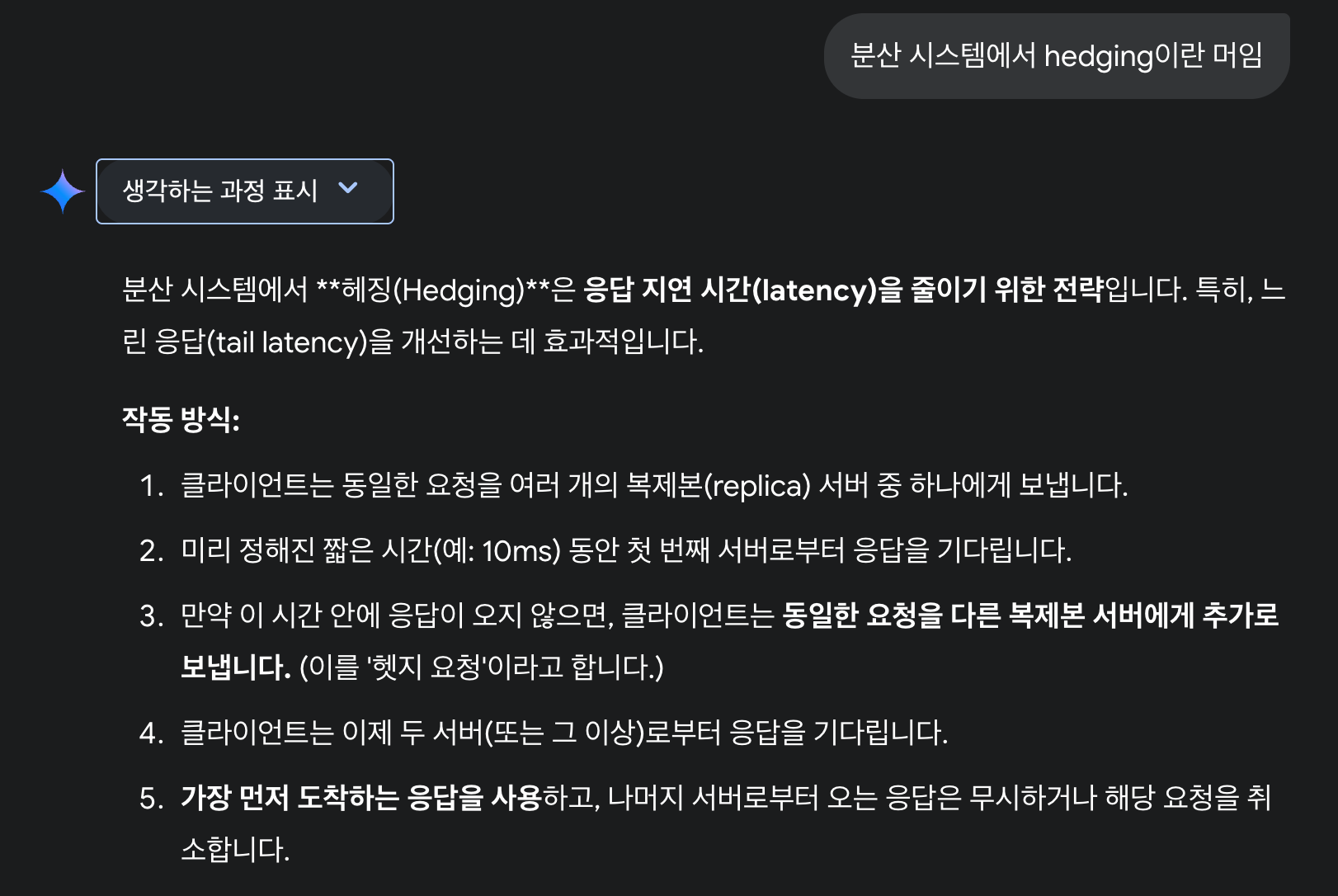
- Approach 2: Per Instance Aggregation
- 각 인스턴스가 주기적으로 메모리에 있는 수를 세어서 디스크로 flush
- flush할 때 Jitter 걸면 경합도 줄일 수 있음
- 인메모리? 서버꺼지면 데이터손실 막을 수가 없음
- 분산되어 있으면 순서 정하기 쉽지 않음. 중간에 리셋같은 거 있으면 골아파짐
- 멱등성도 없음
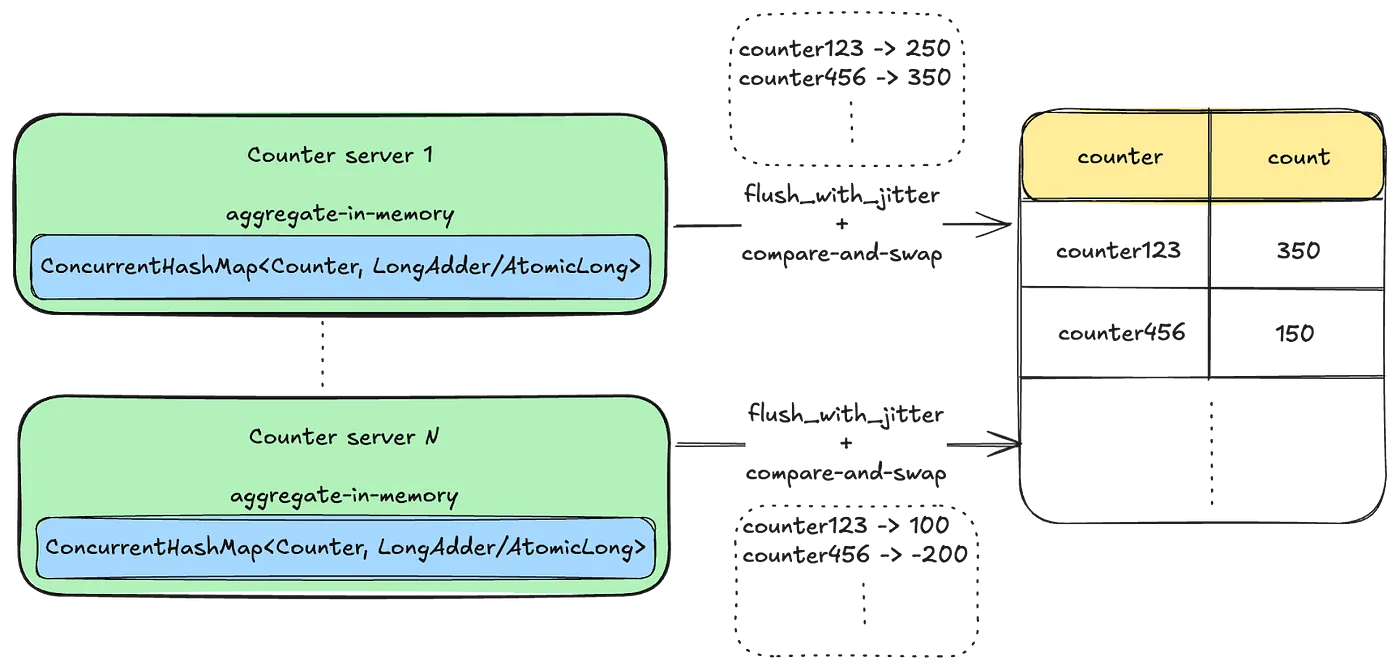
- Approach 3: Using Durable Queues
- 도와줘 카프카형
- 여러 개의 토픽 파티션을 만들고 카운터 키를 특정 파티션에 해싱하여, 동일한 카운터가 동일한 컨슈머에 의해 처리
- 하지만 딜레이가 좀 생기고, 처리량이 증가하면 파티션이 리밸런싱되는 것에 맞춰 대응해줘야하는데 상당히 번거로움
- 특정 time window에 대해서만 이벤트를 recounting 하거나, auditing하기 번거롭다고 함
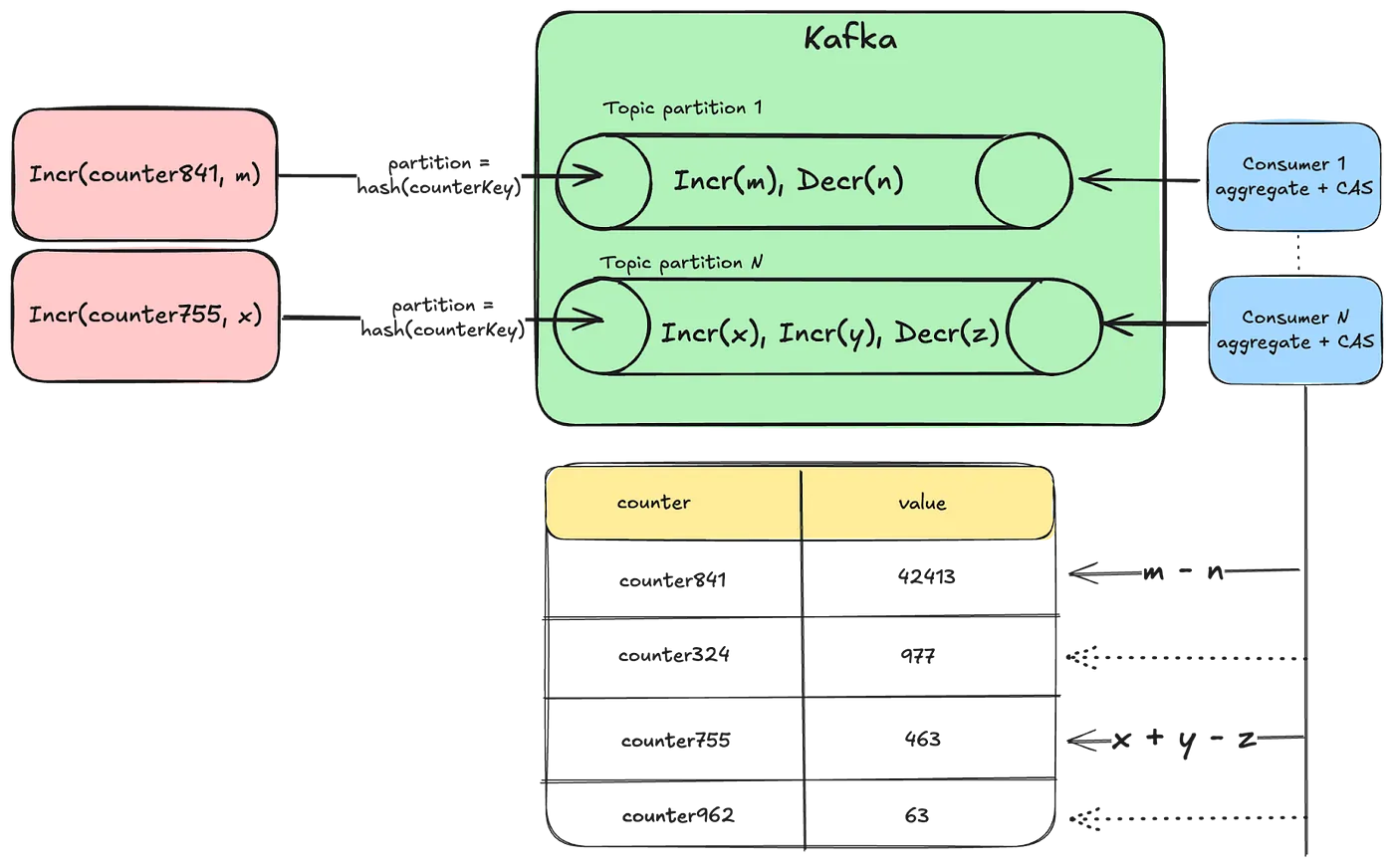
- Approach 4: Event Log of Individual Increments
- Timeseries Data Abstraction을 쓰는 방식
- event_time과 event_id가 있으면 멱등 key도 보장할 수 있다
- 모든 로그를 다 읽는다고? 레이턴시대폭발 저장공간대폭발 와이드파티션대폭발 서버와장창
넷플릭스 형님들의 구현
- 모든 counting activity를 이벤트로 남기고, 백그라운드에서 지속적으로 sliding time window에 따라 aggregate하는 방식
- wide partition 막기 위해 버킷을 잘 나눴다고 합니다
- Timeseries Data Abstraction를 그대로 써서, 얘네가 갖고 있던 장점(레이턴시, 고가용성 등)을 그대로 들고 왔다고 합니다
- Aggregating Count Events
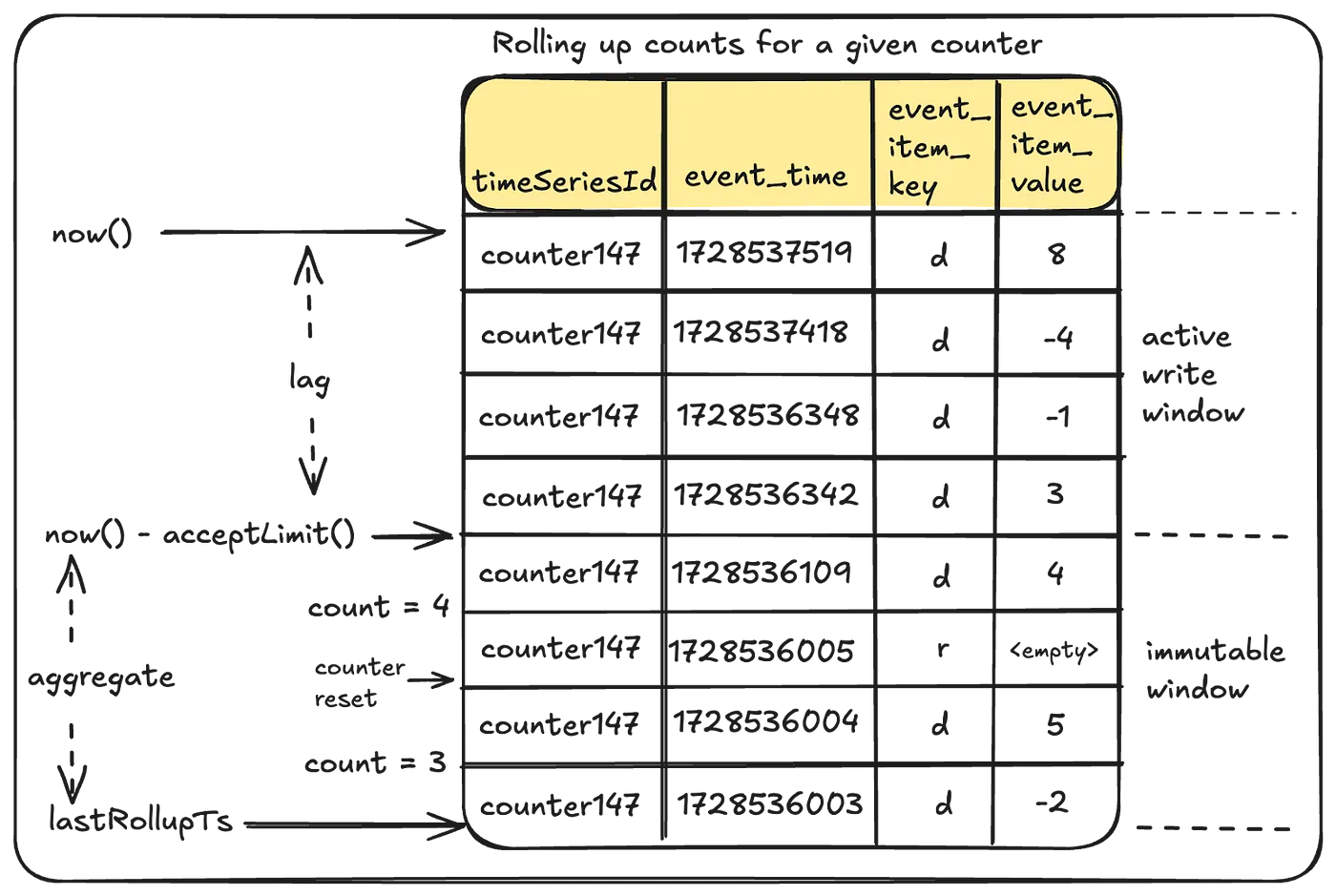
- 모든 read 요청마다 개별 increment를 모두 확인하는 건 너무 느리니, 백그라운드에서 aggregate를 돌자
- 그럼 진행 중인 write는 어떻게 읽나요?
→ eventually consistent라 안 읽을거지롱~
- active한 것들은 읽지 않도록 항상 현재 시간보다 약간 더 전부터 읽음.
- Rollup Store
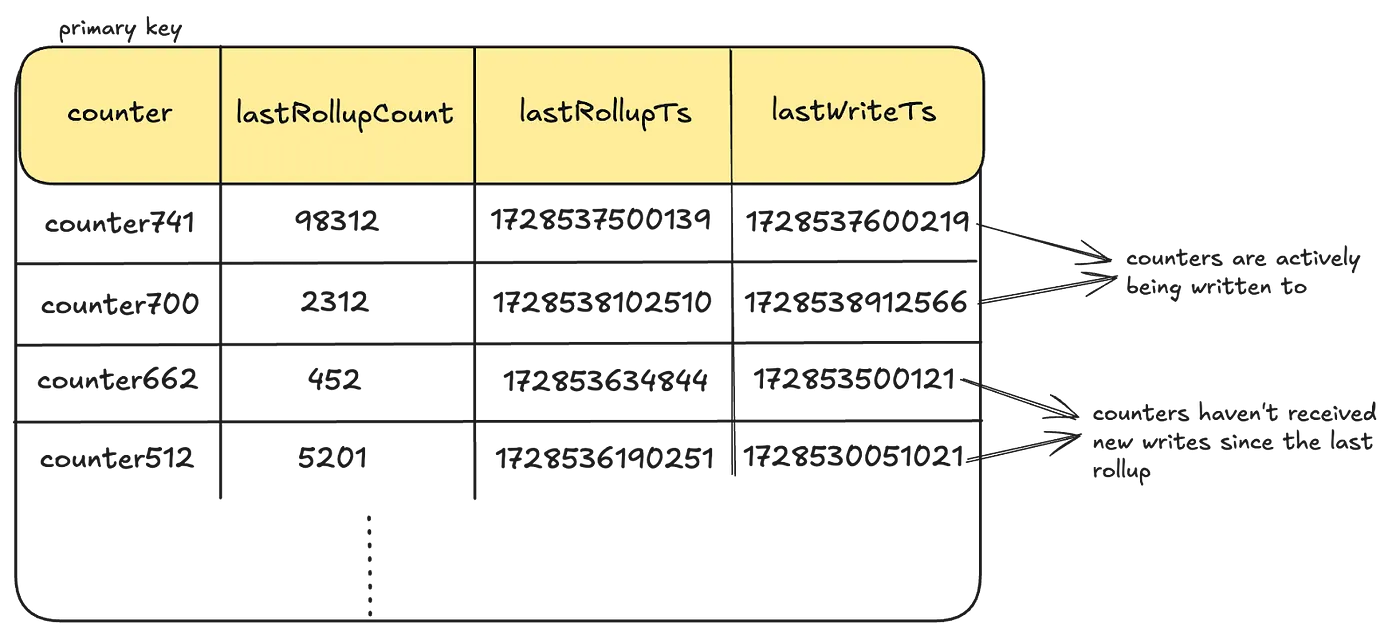
- 읽은 것들을 적절히 저장해줍니다
- increment event를 기록할 때 LastWriteTs도 갱신해서, 이 값이랑 lastRollupTs를 비교해서 aggregate를 수행한다고 합니다
- Rollup Cache

- 읽기 성능을 위해 각 캐시의 값은 EVCache에 저장한답니다
- Rollup Pipeline
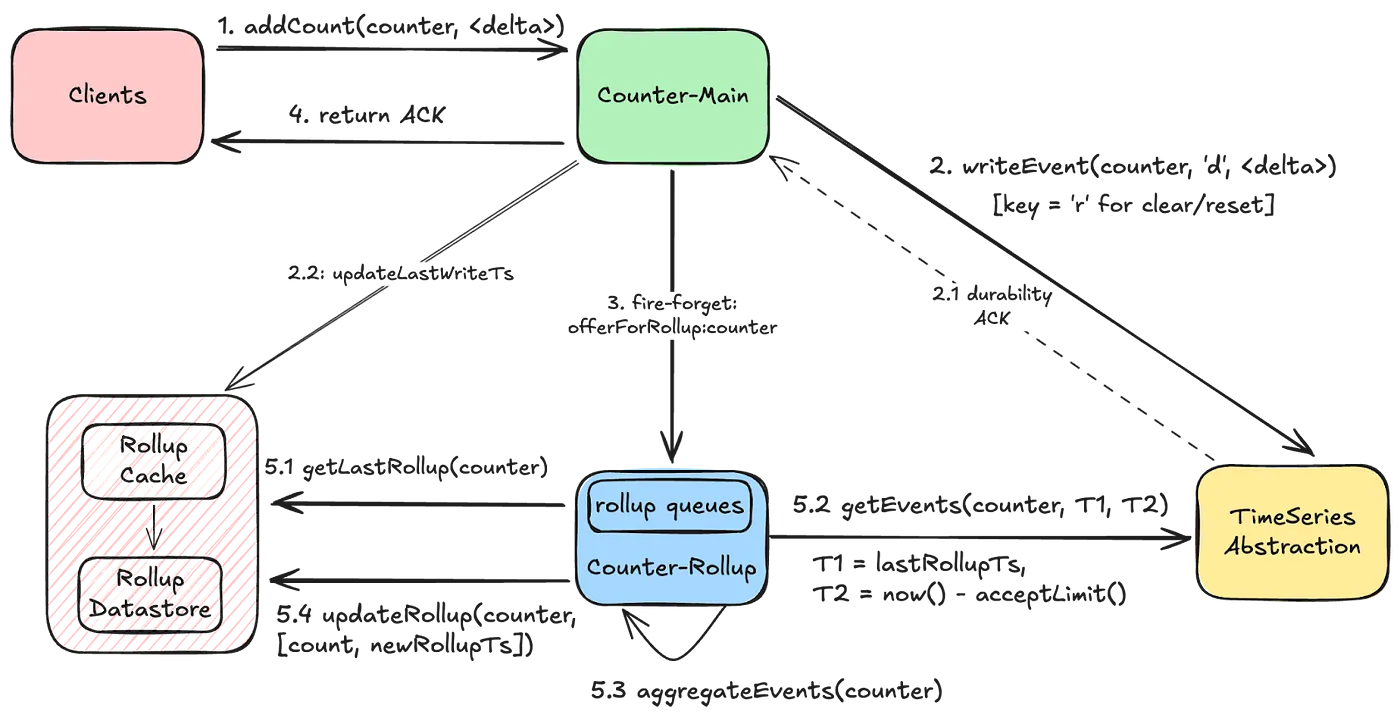
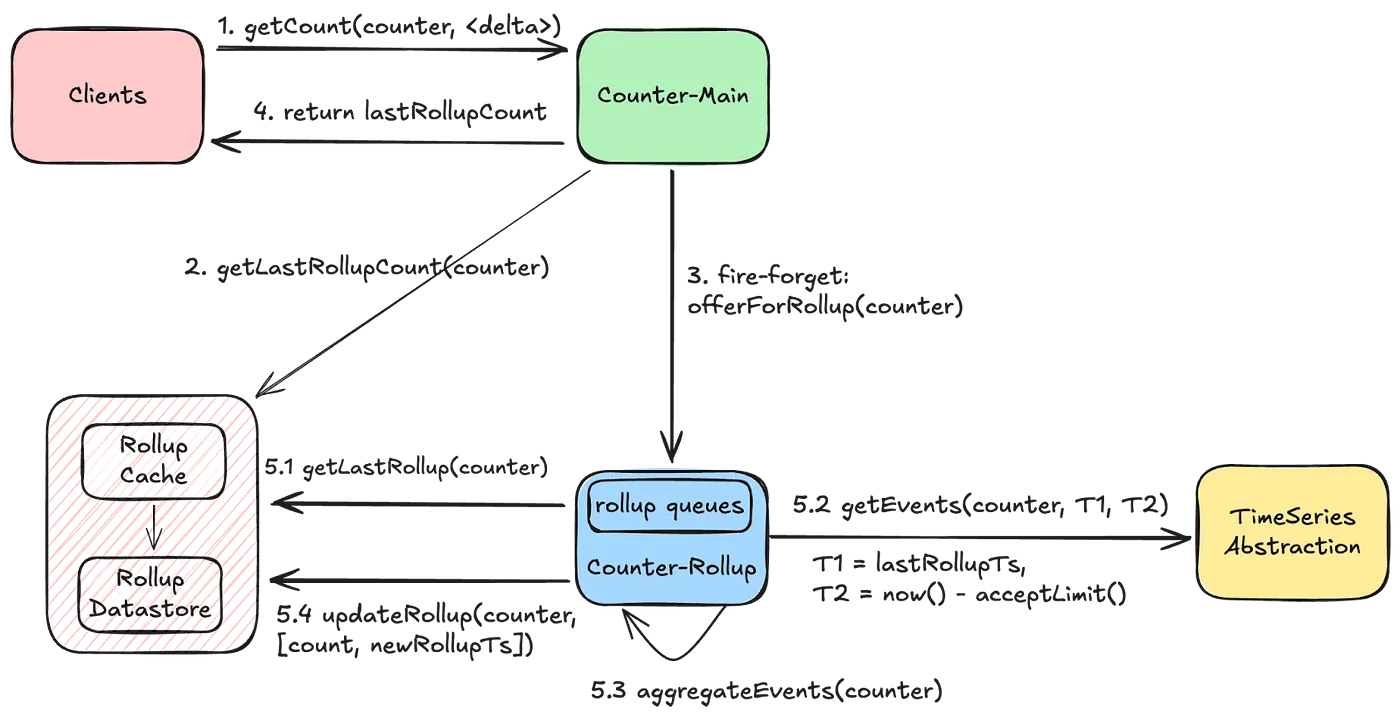
- 카운터에 무슨 요청이든 발생하면 롤업 이벤트를 보냄. 이벤트는 인메모리 큐에 쌓이고 중복을 최대한 제거(주어진 기간 동안 한 번만 aggregate를 실행)
- aggregate를 수행하는 수평확장이 가능함. 성능 저하를 피하기 위해 분산락을 안 잡는 대신, 어느 정도의 중복은 감수하는 듯
- 애초에 aggregate가 time window를 잡고 하니 멱등성이 보장됨
- graceful termination도 적당히 달고
- 저장소 성능을 고려하여 읽는 파티션 수를 적절히 조절함