Kafka
카프카는 분산 메세지큐따위가 아니라 독일의 대문호 프란츠 카프카가 근본이지
는 카프카 1도몰라서 논문이라도 읽어봤다
Abstract
낮은 레이턴시로 많은 양의 로그를 수집/전달할 수 있는 카프카라는걸 만들어 봤어요
만드는 과정에서 conventional하지 않지만 효율적이고 scalable한 디자인을 좀 적용했더니 다른 메세징큐보다 성능이 좋대요
이미 프로덕션에서 기가바이트 단위의 데이터를 매일 처리하고 있어요
1. Introduction
사용자가 활동할 때마다, 또는 시스템 메트릭은 주기적으로 로그에 쌓이니까, 로그를 기반으로 사용자 활동 및 운영 지표를 추적할 수 있음.
- 근데 요새는 이걸 프로덕션 데이터 파이프라인에 태워서 비즈니스 로직에서 활용하는 일이 많아짐 (연관 검색어, 추천, 광고 타게팅, anomaly detection 등)
- 비즈니스 로직에서의 활용성에 따라 수집해야 하는 로그가 덩달아 증가하기도 함 → 로그 양 늘어남 ㅠ
예전(낭만의 시대)에는 서버 접속해서 쌓인 로그 스크랩했지만, 하지만 young하고 mz한(라기엔 10년도 더 된) 분산 로그 수집기들이 나왔다. → 주로 데이터 웨어하우스나 하둡에 저장해서 batch(offline) job
- 하지만 이젠 낮은 레이턴시를 갖는 real-time(online) task도 처리해야 한다.
- 로그 수집기 + 메세징 큐와 비슷한 api + scalability + high throughput = 카프카 탄생
- 로그 데이터를 offline, online으로 모두 사용할 수 있게끔 인프라를 추상화했답니다
2. Related Work
다른 일반적인 MQ는 왜 로그 처리하기에 별로인가?
- 로그 프로세싱에서 불필요한 요소에 포커스를 맞춤 (transactional/atomic이라던지, ack라던지)
- 있어서 나쁠 건 없겠지만 로그 처리에 있어서는 굳이..?의 영역임. 로그 몇개 날아가도 세상 망하는거 아니다(진짜 논문에 이렇게 적혀있어요 ㄷㄷ)
- throughput 중점적으로 디자인되지 않았음
- 보통 메세징큐는 쏘자마자 받아서 처리하는 것을 상정하므로, 메세지가 쌓이면 성능이 떨어짐
- 그래서 주기적인 대규모 로드가 걸리면 취약함
반면 다른 분산 로그 수집기들은 대개 offline task를 처리하기에 적합하고, 불필요한 정보까지 노출함
- 또한 보통은 메세지를 push하는데, 카프카는 pull로 받아온다.
- 그래서 메세지가 flooding되어서 머신이 터지는 일을 피할 수 있음
3. Architecture and Design Principle
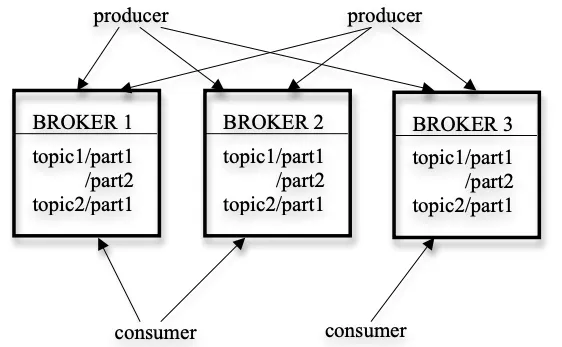
topic: 특정 타입의 메세지 스트림
broker: producer가 publish한 메세지들이 저장되는 서버들. 각 서버는 한 개 이상의 파티셔닝된 토픽을 저장
consumer는 broker에서 1개 이상의 topic을 subscribe하고, pull해서 메세지를 당겨옴
3.1. Efficiency on a Single Partition
Simple Storage
- 토픽의 각 파티션은 로그에 해당하며, 로그는 거의 비슷한 크기의 파일 세그먼트로 나뉜다.
producer가 메세지를 publish하면, 브로커는 메세지를 마지막 파일 세그먼트에 적절히 추가한다.
더 나은 성능을 특정 수의 메세지가 publish되거나 일정 시간이 지나면 위해 파일 세그먼트를 디스크에 flush한다. flush된 메세지만 cunsumer에게 노출된다. (대충 disk flush를 bulky하게 한다는 말인듯)
- 다른 메세징 시스템과는 달리 카프카의 메세지는 명시적인 id가 없다
대신 각 메세지는 로그 안 논리적 오프셋으로 구분하며, 랜덤 액세스가 가능한 구조를 유지해야 하는 오버헤드를 피할 수 있다. (대신 특정 메세지의 오프셋을 알려면 그 전 메세지의 오프셋 + 크기를 알아야 함)
- consumer는 특정 파티션의 메세지를 순차적으로 읽기 때문에, 마지막 메세지의 오프셋 + 크기를 통해 다음 에 읽을 메세지의 오프셋을 알아낼 수 있음
이렇게 알아낸 오프셋 + 읽어올 바이트로 구성된 비동기 pull 요청을 보내게 됨
- 브로커는 정렬된 오프셋 목록을 sorted list로 가지고 있고, 요청이 오면 오프셋 목록을 기반으로 파일 세그먼트에서 메세지를 찾아 consumer에게 보내줌
Efficient transfer
- producer는 한 번에 한 메세지만 submit하지만, consumer의 각 pull 요청마다 거의 수 백 kb에 달하는 메세지를 이터레이션 돌아야 한다
- 카프카는 메모리에 메세지를 캐싱하지 않는 대신, 운영체제 레벨의 page 캐시를 믿는다.
- 메세지가 이중으로 캐싱되는 걸 피하기 위함
- broker 프로세스가 재시작해도 캐시가 남아있음 (cold start 방지)
- GC overhead가 줄어들기 때문에 VM 기반 언어에서도 효율적
- producer, consumer가 모두 순차적으로 메세지에 접근하므로, 운영체제 기반의 캐싱 전략(write-through, read-ahead)이 효과적으로 통함!
- producer, consumer 모두 성능이 TB 단위의 데이터에 대해서도 linear하게 비례함
- 동일한 메세지가 여러 consumer에서 여러 번 consume될 수 있음.
일반적으로 소켓을 통해 로컬 파일을 원격으로 보내면 다음의 단계를 거침
- os가 스토리지에서 데이터를 읽어와 페이지 캐시에 올림
- 페이지 캐시에서 애플리케이션 버퍼에 복사
- 애플리케이션 버퍼에서 커널 버퍼에 복사
- 커널 버퍼가 소켓을 통해 데이터를 전송
- 4개의 복사, 2개의 시스템 콜
- 근데 UNIX 계열에 있는 sendfile API를 써서 파일 채널에서 소켓 채널로 데이터를 바로 쏠 수 있음. 2개의 복사, 1개의 시스템 콜이 생략됨
Stateless broker
- 다른 메세징 시스템과는 다르게, consumer가 메세지를 얼마나 consume했는지를 broker에서 관리하지 않는다.
- 따라서 브로커의 복잡도와 오버헤드를 줄일 수 있다
- 하지만 메세지가 잘 소비되었는지 알 수 없어서 어떤 메세지를 삭제해야 할 지 결정하는 게 좀 애매함
- 보통 메세지 보존 정책으로 time-based SLA를 사용함 (일정 기간 이상 브로커에 보관된 메세지 삭제)
- 대부분의 경우 일정 시간이 지나면 알아서 지워지기 때문
- 이러한 디자인 덕분에 consumer가 이전 offset의 데이터를 불러오는 것도 가능함
- 서비스에 잠깐 문제가 생겼는데 고쳐진 후 다시 불러온다던지 등등
3.2. Distributed Coordination
- 분산 환경에서, producer는 무작위로, 또는 partitioning key 혹은 partitioning function에 따라 선택된 파티션에 메세지를 publish할 수 있다.
- 한 개 이상의 consumer가 모여 consumer group을 구성하고, consumer group 안의 consumer는 구독된 topic을 동시에 consume한다
- 한 consumer group 안에서 각 메세지는 임의의 한 consumer에게만 날아간다.
- 서로 다른 consumer group은 독립적으로 구독한 message를 소비하며, 이들 간에 coordination은 필요하지 않다.
⇒ 오버헤드를 줄이기 위한 디자인
- 한 토픽에서 특정 파티션의 메세지들은 각 consumer group당 한 consumer에게만 들어감.
- 만약 여러 consumer가 받을 수 있는 스펙이였다면 그걸 추적하는 데 또 오버헤드가 생겼을 것
- 파티션을 적당히 많이 잡으면 consumer간 로드 밸런싱도 가능하다고 함..?
- master node가 따로 없고, consumer들이 알아서 node 선택
- master failure 걱정할 필요 없다
- 조정을 용이하게 하기 위해 Zookeper 사용
- Zookeeper의 기능
- file system api
- 특정 path에 observer를 붙여서, path의 children이나 값이 변경되면 노티를 줄 수 있다
- 특정 path를 생성한 클라이언트가 사라지면 path도 사라지게 할 수 있음 (ephemeral)
- 데이터의 여러 서버에 replicate해서 고가용성
- 이런 일에 사용
- broker 및 consumer 추가 및 제거, rebalance
- 각 브로커 또는 consumer가 시작되면 zookeeper에 있는 레지스트리에 등록함
- broker registry: host name, port, 토픽들, 파티션들
- consumer registry: consumer group 정보(어떤 consumer가 있는지, 얘네가 구독하는 topic)
- ownership registry: 구독된 모든 파티션에 대한 path가 있고, path의 값은 해당 파티션을 구독하는 consumer의 id
- offset registry: 각 파티션에서 마지막으로 consume된 메세지의 offset
- broker, consumer, ownership registry에 생성되는 path는 ephemeral하고, offset registry에 생성되는 path는 persistent
- 각 브로커 또는 consumer가 시작되면 zookeeper에 있는 레지스트리에 등록함
- 각 파티션-consumer의 relationship과 consume된 offset 트래킹
- 브로커가 죽으면 broker registry에 등록된 모든 파티션이 자동으로 지워짐
- consumer가 죽으면 consumer, ownership registry의 모든 엔트리를 잃음
- 노티 기능을 통해 broker registry, consumer registry에 뭔가 변경이 일어날 때마다 consumer가 노티받음
- consumer는 이런 노티를 받으면 rebalance 알고리즘에 따라 다른 파티션을 선택하여 계속 데이터를 읽어올 수 있음
- 근데 여러 consumer가 있는 consumer group에서는 이 노티가 약간씩 다른 시점에 올 수 있고, 이미 한 consumer가 소유하고 있는 파티션을 다른 consumer가 고를 수 있음
- 이러면 이미 갖고 있는 consumer가 그 파티션을 release하고 약간 기다렸다가 rebalance를 다시 시작 (웬만하면 잘 된다고 합니다)
- broker 및 consumer 추가 및 제거, rebalance
- Zookeeper의 기능
3.3. Delivery Guarantees
- 카프카는 at-least-once delevery를 보장한다고 함
- exactly-once delivery를 달성하기 위해 2pc 등 불필요한 것들이 너무 많음
- 대부분의 경우 한 번씩 도착하긴 함
- 간혹 consumer 프로세스가 graceful shutdown을 못하는 경우, 파티션을 물려받은 consumer가 이미 consume된 메세지를 다시 처리해야 하는 경우가 있을 텐데, 그 때 유용하다고 함
- 한 파티션 안에서 오는 메세지는 순서가 보장되지만, 서로 다른 파티션에서 오는 메세지들의 순서는 보장되지 않음
- 각 메세지에 대한 CRC를 저장해서 로그 오염을 방지함
- 브로커가 죽으면 스토리지에 저장된 메세지는 못 쓰게 된다고 하는데, 논문 쓰일 당시에는 브로커마다 리플리케이션 저장하는 기능은 없었나봄