Timeseries data abstraction
Introducing Netflix’s TimeSeries Data Abstraction Layer
양이 왜이렇게 많아
Introduction
넷플릭스 형님들께서 low-latency로 대량의 이벤트 데이터를 처리할 수 있게끔 만든 추상화 계층
메트릭, 히스토그램 등 일반적인 준실시간 유즈케이스로 사용하는 게 아니라, 임시적인 이벤트 데이터를 높은 throughput과 낮은 latency로 처리하기 위해 사용
어따씀
- 마이크로서비스간 통신 로깅 및 인사이트
- 사용자가 페이지에서 하는 검색, 플래이백 등 모든 User Interaction을 기록하고 추천 알고리즘에 전달
- 외에도 몇 개 있으나… 조금이라도 실시간성이 중요한 기능에는 사용하지 않는 듯
Challenges
- 여기서 처리하고자 하는 이벤트의 예시는 비디오 시청 이벤트, 인게임 이벤트(이녀석들 게임도 하나보네요), 넓게는 마이크로서비스 네트워크 이벤트등도 포함될 수 있음
- 근데 이런거 처리하려면 다음과 같은 요구사항이 필요함
- 가용성 유지하면서 초당 1000만 건의 write를 처리
- 페타바이트 단위 데이터를 저장하고, 2자릿수 밀리초 내에 결과를 반환할 수 있어야 함
- 세계 어디서든 읽고쓰기 가능
- 유동적인 파티셔닝 전략
- 트래픽 급증 대응
- 근데 이제 최대한 저렴하게
- 넷플릭스 정도 되는 서비스는 역시 단위부터가 다르다… 짐바브웨 화폐를 보는 듯한
Data Model
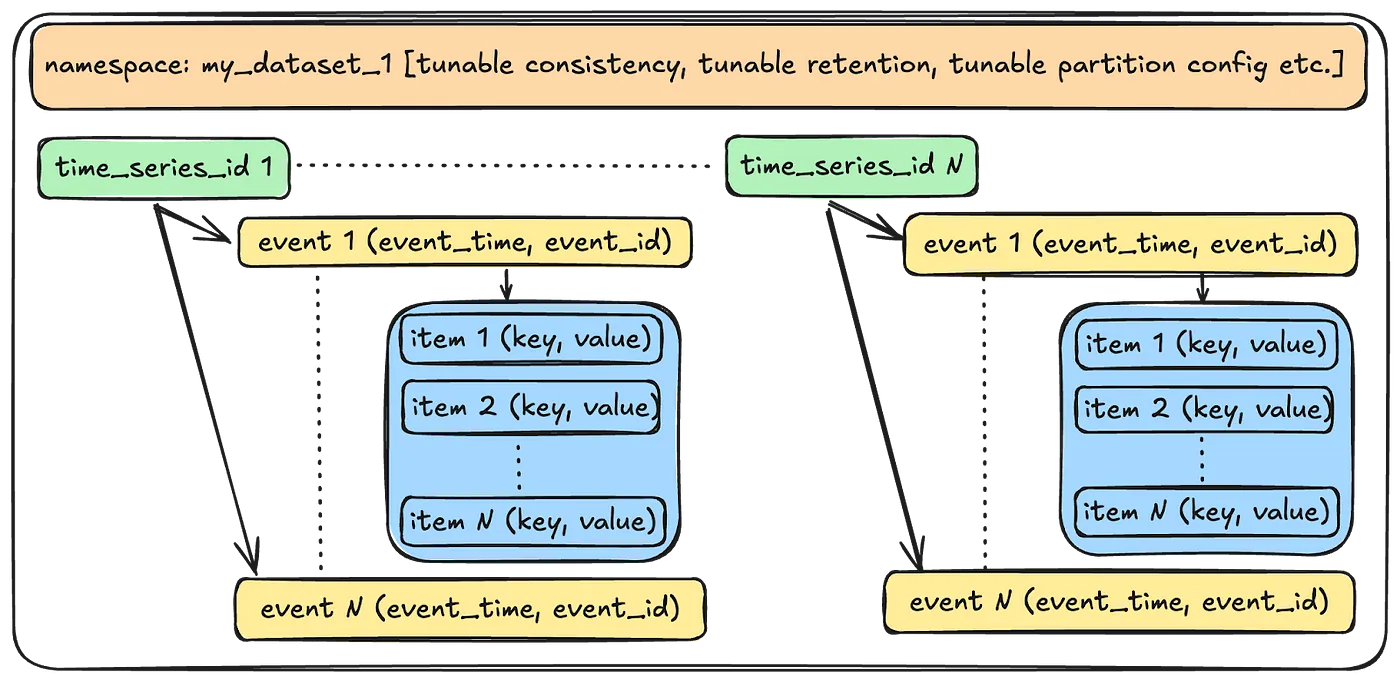
적당한 캡슐화와 효율적인 쿼리가 가능한 모델
- Event Item: 특정 이벤트에 대한 데이터를 저장하기 위한 key-value 페어. e.g. {“device_type”: “ios”}
- Event: 여러 Event Item으로 이루어짐. 타임스탬프(event_time)와 식별자(event_id)의를 조합하여 고유한 키 생성
- Time Series ID: 데이터 보존 기간 동안 저장되어 있는 한 개 이상의 Event 모음
- Namespace: 대충 예상 가는 그것. Time Series ID로 이루어진 전체 데이터세트의 모음이고, 네임스페이스별로 설정 튜닝 가능
API
- Write
- WriteEventRecords: fire-and-forgot 및 약간의 손실을 허용하는 endpoint
- WriteEventRecordsSync: 위 요청의 sync 버전. 정확히 write를 해야 할 때 사용할 듯
요청 JSON
{ "namespace": "my_dataset", "events": [ { "timeSeriesId": "profile100", "eventTime": "2024-10-03T21:24:23.988Z", "eventId": "550e8400-e29b-41d4-a716-446655440000", "eventItems": [ { "eventItemKey": "deviceType", "eventItemValue": "aW9z" }, { "eventItemKey": "deviceMetadata", "eventItemValue": "c29tZSBtZXRhZGF0YQ==" } ] }, { "timeSeriesId": "profile100", "eventTime": "2024-10-03T21:23:30.000Z", "eventId": "123e4567-e89b-12d3-a456-426614174000", "eventItems": [ { "eventItemKey": "deviceType", "eventItemValue": "YW5kcm9pZA==" } ] } ] }Show⯆ - Read
- ReadEventRecords: namespace, timeSeriesId, time range 및 optional filter를 주고 매칭되는 이벤트를 받아옴
요청 JSON
{ "namespace": "my_dataset", "timeSeriesId": "profile100", "timeInterval": { "start": "2024-10-02T21:00:00.000Z", "end": "2024-10-03T21:00:00.000Z" }, "eventFilters": [ { "matchEventItemKey": "deviceType", "matchEventItemValue": "aW9z" } ], "pageSize": 100, "totalRecordLimit": 1000 }Show⯆ - SearchEventRecords: 대략 elasticsearch스러운 쿼리 (eventually consistent)
요청 JSON
{ "namespace": "my_dataset", "timeInterval": { "start": "2024-10-02T21:00:00.000Z", "end": "2024-10-03T21:00:00.000Z" }, "searchQuery": { "booleanQuery": { "searchQuery": [ { "equals": { "eventItemKey": "deviceType", "eventItemValue": "aW9z" } }, { "range": { "eventItemKey": "deviceRegistrationTimestamp", "lowerBound": { "eventItemValue": "MjAyNC0xMC0wMlQwMDowMDowMC4wMDBa", "inclusive": true }, "upperBound": { "eventItemValue": "MjAyNC0xMC0wM1QwMDowMDowMC4wMDBa" } } } ], "operator": "AND" } }, "pageSize": 100, "totalRecordLimit": 1000 }Show⯆ - AggregateEventRecords: Search랑 비슷한데 aggregation 수행 (distinct 등)
요청 JSON
{ "namespace": "my_dataset", "timeInterval": { "start": "2024-10-02T21:00:00.000Z", "end": "2024-10-03T21:00:00.000Z" }, "searchQuery": {...some search criteria...}, "aggregationQuery": { "distinct": { "eventItemKey": "deviceType", "pageSize": 100 } } }Show⯆
- ReadEventRecords: namespace, timeSeriesId, time range 및 optional filter를 주고 매칭되는 이벤트를 받아옴
Storage
- 주 저장소(Apache cassandra)와 인덱스 저장소(elasticsearch)로 구성됨
- 주 저장소 - 안전한 write 및 주된 데이터 read
- 보조 저장소 - search 및 aggregate에 사용
- 굳이~ cassandra랑 elasticsearch 안 써도 되게끔, 계층 분리 잘 해뒀다고 자랑 적혀있음;;
주 저장소
- Partitioning Scheme
- 이벤트 데이터 짱 많음;; 파티셔닝 잘 해야 함
- 넷플릭스는 일정한 time window를 두어 파티셔닝
- 전체 데이터셋 스캔하지 않고 쿼리 가능
- 오래된 데이터 적당히 처리하기 편함
카산드라의 wide partition 문제 해결

기강잡기
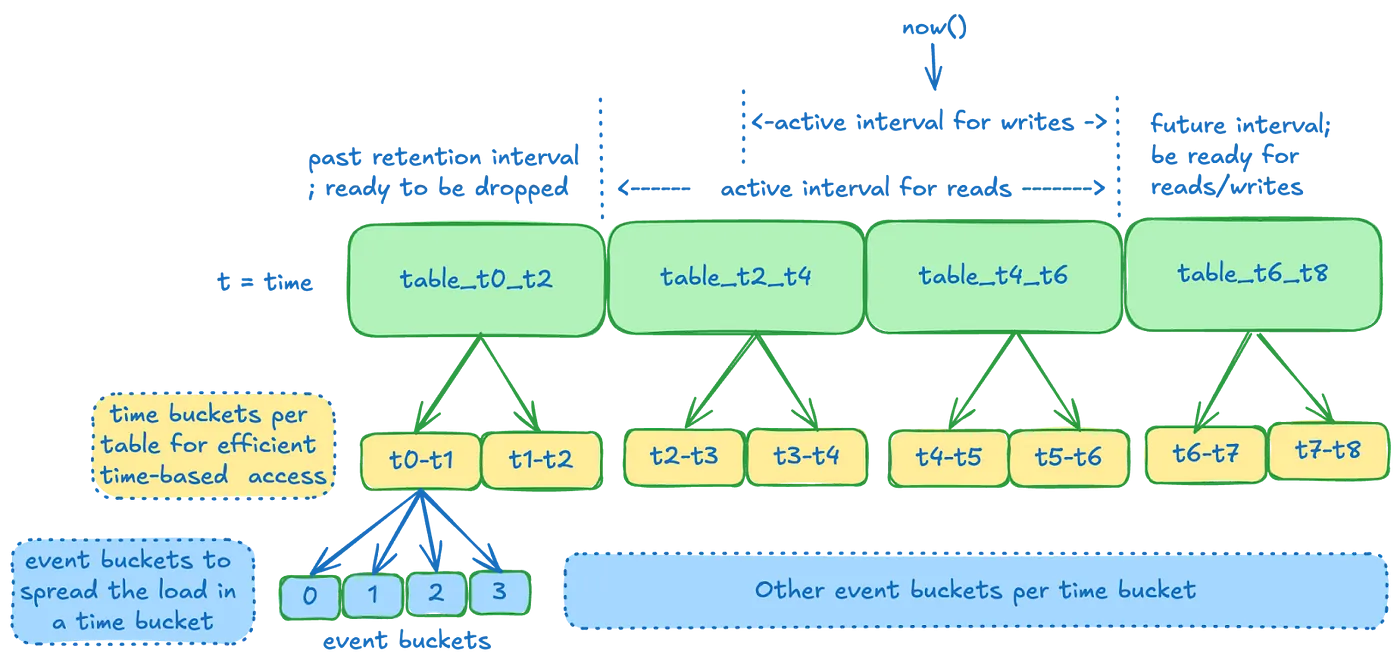
- Time Slice
- 데이터 보존 단위로, 카산드라 테이블에 매핑됨. 이벤트는 event time에 따라 테이블에 저장됨.
- slice는 공백 없이 존재
- 전체 테이블을 딸깍 날리면 outdated된 이벤트가 날아간다!
- 카산드라 성능을 위해 TTL을 사용하지 않았음. 카산드라는 내부적으로 Tombstone이라는 것을 통해 TTL을 관리하는데, 개별 이벤트에 모두 TTL 걸리면 (특히 scan할 때) 성능 저하가 있음
- Time Bucket
- Time Slice 내에서, event time 기준으로 한번 더 파티셔닝됨. range query를 더 효율적으로 하기 위함
- 대신 full scan은 오래 걸리긴 하는데 대부분 일부분만 읽고, 설령 다 읽어도 적당히 병렬로 읽으면 문제 없슴
- Event Buckets
- 보통 특정 time bucket만 bursty하게 write가 몰림. 이걸 분산하기 위해 time bucket 안에서도 한번 더 파티셔닝
- Data Table
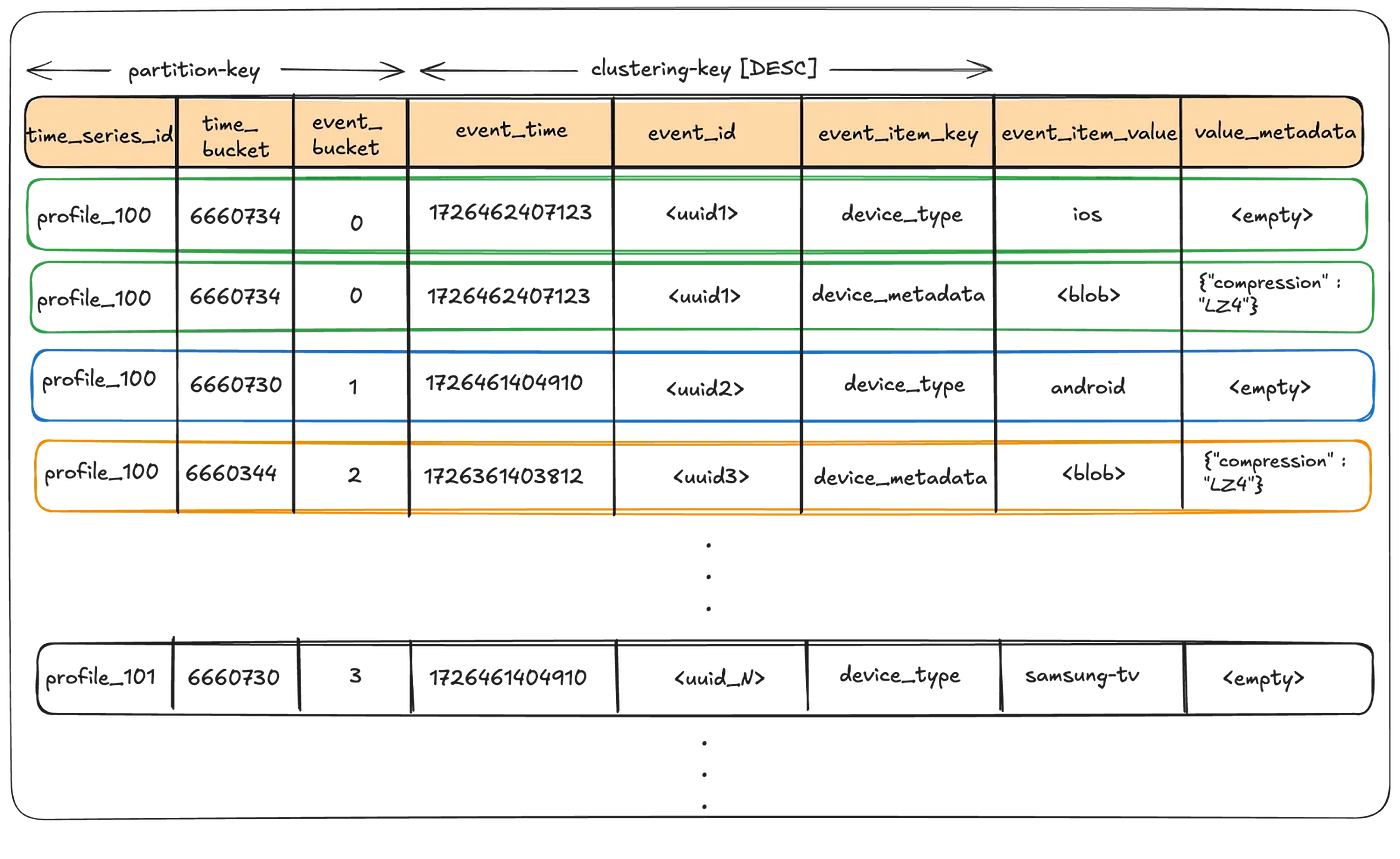
- time series id, time bucket, event bucket을 파티션 키로 설정하여 hot partition 예방
- time series id와 event time을 기반으로, 저장될 테이블에 도달
- 각 이벤트는 clustering key로 읽고 싶은 순서대로 정렬되어 저장됨
- 여러 테이블에서 scatter-gather패턴으로 분산 읽기가 가능
- Metadata Table
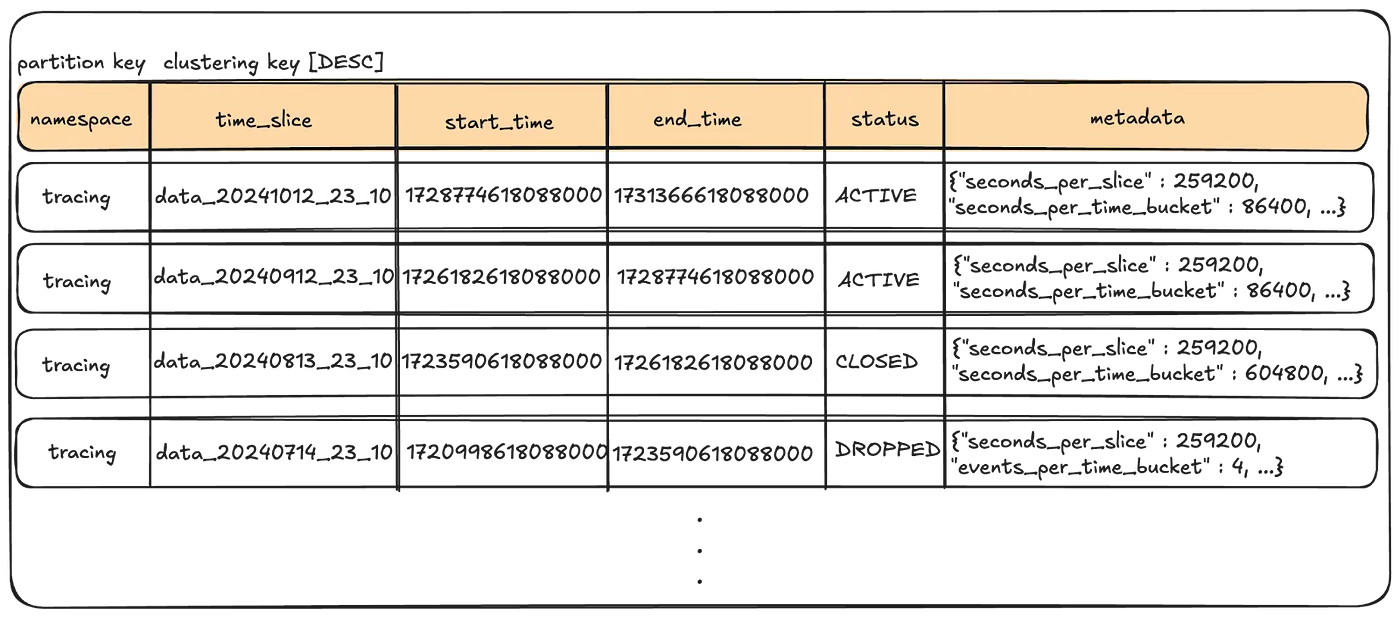
- namespace마다 존재하는, 각 time slice에 대한 설정 저장
- 범위, 저장 기간, 압축 등등등
인덱스 저장소
- PK가 아닌 필드로 접근하기 위함
- 이벤트에서 필요한 필드를 elasticsearch에 인덱싱
- 처리량에 따라 리버스 인덱스로 쓰거나, 그냥 이벤트를 cassandra 대신 elasticsearch에 저장할 수도 있다고 함
Design Principles
이벤트 멱등성
- 모든 엔드포인트에서 멱등적이길 원했음 (따닥방지)
- event_time, event_id and event_item_key를 잘 조합해서 개별 time series에 대한 멱등성을 제공
Partial Return
- 간혹 클라이언트가 정확성보단 응답속도가 더 중요할 수도 있음. 요청에 명시
Adaptive Pagination
- 모든 read는 기본적으로 8개의 버킷을 병렬적으로 읽도록 팬아웃
- 근데 특정 파티션에 데이터가 너무 몰려있다? 그러면 fanout factor를 줄인다 (hot partition 방지하기 위함인듯)
- 물론 너무 퍼져 있으면 늘어난다
Limited Write Window
- 너무 오래된 이벤트의 write는 방지할 수 있어야 한다
- acceptLimit 라는 파라미터를 두어서 관리하자
Buffering Writes
- 워크로드 관리용. 갑자기 너무 요청이 와바박 들어오면 파티션 키별로 인메모리 큐에 넣고 일정 시간에 걸쳐 분산해주자
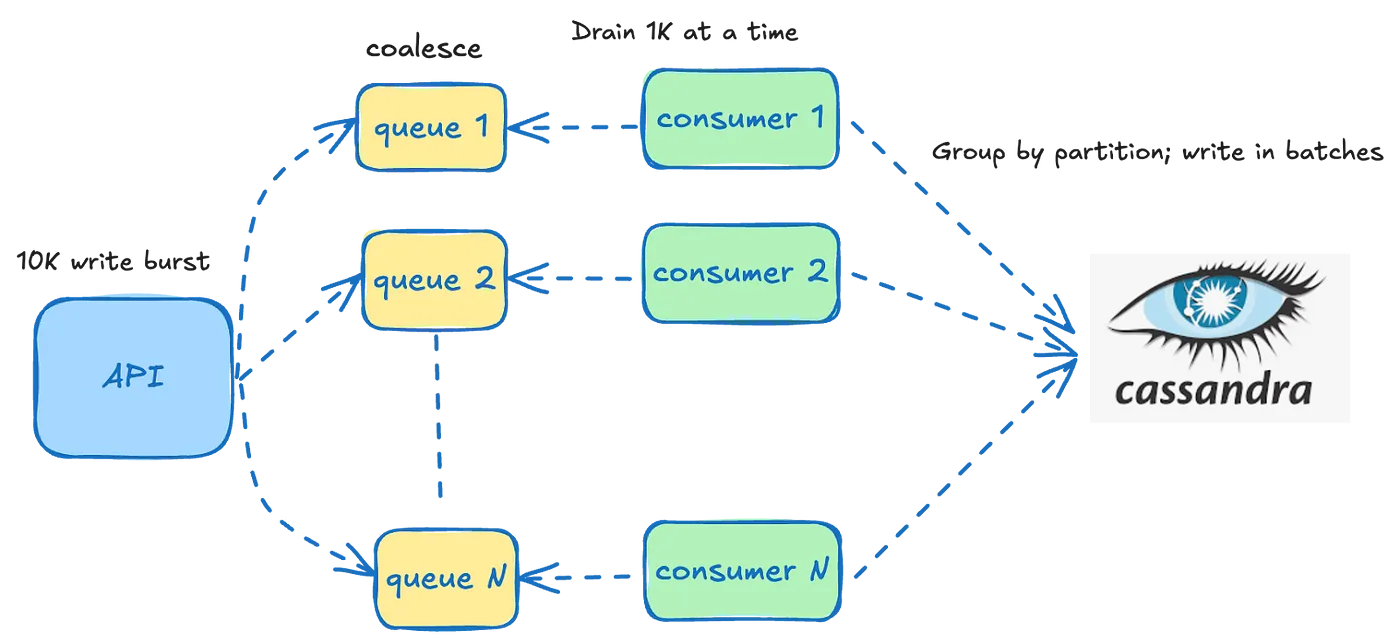
- 물론 인스턴스 죽으면 인메모리 큐도 싹 다 증발되니, data loss를 허용하는 유즈케이스에 대해서만 사용이 가능
Dynamic Compaction
- time slice가 write window를 벗어난다? 바로 압축 때려서 성능을 올린다.
후기
- 다이어그램 손글씨는 진짜 참을수가 없